Mairaデータセット管理
このチュートリアルでは、Mairaデータセット管理用のすべてのエンドポイントと、それらの使用方法について説明します。 全てのエンドポイントは、sandboxの"MyGPT Dataset"セクションで確認できます。
コンセプト
- データセット: データセットとは「ドキュメント」(下記にて説明)の集合です。例えば、1つの"データセット"には、会社の住所、連絡先情報、製品説明、ポリシーといった会社情報が含まれる"ドキュメント"が複数格納されていることがあります。他のデータセットには、従業員情報や顧客情報などが含まれることがあります。なぜ異なるデータセットを持つ必要があるのかは後ほど説明いたします。各データセットには固有のIDが設定されています。
- ドキュメント: 会社の住所や製品説明といった"データセット"内の個々の情報単位です。これらのドキュメントはアプリケーションのトレーニングに使用されます。Mairaの応答には、応答を生成するために参照されたドキュメントのリストが含まれています。各"ドキュメント"には、同じデータセット内で固有のIDXという識別子があります。
データセット例
こちらは、4つのドキュメントを含むサンプルデータセットです。:
| idx | タイトル | 内容 |
|---|---|---|
| 1 | Gigalogyの歴史 | Gigalogyは東京で設立されました。2020年1月:Gigalogyはダッカにオフィスを開きました。2024年:Mairaをリリースしました。 |
| 2 | Gigalogy東京オフィスの住所 | Gigalogy本社は、105-6923 東京都港区虎ノ門4-1-1 23階にあります。 |
| 3 | 東京オフィスの電話番号 | 電話: +813-4500-7914 |
| 4 | 主な製品 | パーソナライザーとMaira |
このデータセットには4つのドキュメントがあります。最初の列である「idx」は、各ドキュメントに対する固有の識別子の列です。各ドキュメントは複数のキーを持つことができます。この例の場合、タイトルと内容があります。
次に、Mairaのデータセットとドキュメントの管理に関する操作やエンドポイントについて説明いたします。
データセットとドキュメントを表示
データセットを"閲覧"できるのは、作成した後のみです。"データセット"や"ドキュメント"の作成および管理に関しては、後のセクションで説明します。
すべてのデータセットのリストを表示
全データセットの一覧を閲覧するには、エンドポイント GET /v1/gpt/datasets を使用します。すべてのデータセット一覧とそのメタデータを入手できます。
start パラメータを使用して、先頭に表示する結果のインデックス番号を指定し、size パラメータで表示する結果の数を指定します。
クエリパラメータ keyword を使用して特定のデータセットをフィルタリングできます。ここでデータセットのタグを使用してフィルタリングすることもできます。
データセットの概要を表示
特定のデータセットの概要を表示するには、GET /v1/gpt/datasets/{dataset_id} を使用してください。レスポンスには、データセットのメタデータとともに、保持しているドキュメントの概要が含まれます。以下に例を示します。:
{
"response": {
"dataset": {
"name": "サンプルデータセット",
"idx_column_name": "id",
"is_idx_fillup_if_empty": true,
"secondary_idx_column": "secondary_id",
"image_url_column": "image_url",
"description": "これはデモンストレーション用に使用されるサンプルデータセットです。",
"dataset_id": "12345",
"filterable_fields": ["field1", "field2", "field3"],
"created_at": "2024-08-30T10:00:00.000000+09:00",
"updated_at": "2024-08-30T10:05:00.000000+09:00",
"documents_count": {
"total": 1000,
"active": 980,
"text_trained": 960,
"image_trained": 20
}
}
}
}
documents_countのオブジェクトには、ドキュメントの総数とそのステータスが表示されます。document_count のオブジェクトについて詳しく説明いたします。:
- total: データセット内のドキュメントの総数を表示します。
- active: データセット内でアクティブなドキュメントの数を表示します。アクティブなドキュメントは、トレーニングされていれば回答生成に使用され、未トレーニングの場合、次のトレーニングサイクルでトレーニングされます。非アクティブ(アーカイブ済み)のドキュメントは回答生成には使用されません。
- text_trained: トレーニング済みデータセットの数を表示します。特定のドキュメントがデータセット内でトレーニングされていない理由はいくつか考えられます。例えば、データセットに後から追加されたドキュメントがあり、その後にデータセットがトレーニングされなかった場合です。この場合、未トレーニングのドキュメントが存在し、これらは回答生成に使用されません。
- image_trained:
text_trainedと同様に、画像トレーニングが行われたドキュメントの数を示します。
テキストトレーニングされたドキュメントは、POST /v1/maira/ask エンドポイントを介して回答生成に使用され、画像トレーニングされたドキュメントは、POST /v1/maira/vision エンドポイントを介して回答生成に使用されます。
データセットのすべてのドキュメントを表示
特定のデータセットのすべてのドキュメントを表示するには、エンドポイント GET /v1/gpt/datasets/{dataset_id}/documents を使用してください。以下にレスポンスの例を示します。:
{
"response": {
"total_hits": 521,
"returned_hits": 3,
"documents": [
{
"id": "123e4567-e89b-12d3-a456-426614174000",
"data": {
"idx": "doc001",
"content": "ドキュメント1のサンプル内容です。",
"tokens": "50"
},
"active_status": "active",
"status": "trained",
"image_train_status": "trained",
"created_at": "2024-01-01T12:00:00+09:00",
"updated_at": "2024-01-02T12:00:00+09:00"
},
{
"id": "234f5678-f89c-23d4-b567-526725274111",
"data": {
"idx": "doc002",
"content": "ドキュメント2のサンプル内容です。",
"tokens": "40"
},
"active_status": "active",
"status": "trained",
"image_train_status": "trained",
"created_at": "2024-01-02T13:00:00+09:00",
"updated_at": "2024-01-03T13:00:00+09:00"
},
{
"id": "345g6789-g90d-34e5-c678-627836375222",
"data": {
"idx": "doc003",
"content": "ドキュメント3のサンプル内容です。",
"tokens": "45"
},
"active_status": "active",
"status": "trained",
"image_train_status": "trained",
"created_at": "2024-01-03T14:00:00+09:00",
"updated_at": "2024-01-04T14:00:00+09:00"
}
]
}
}
このエンドポイントでは、以下のクエリパラメータを使用して検索結果をカスタマイズできます。
- keyword - データセットおよびドキュメント内の完全一致するフレーズ検索。検索はフレーズ全体が完全一致する結果を返します。
- sort_by_created_at:
ascまたはdescを選択 - sort_by_created_at:
ascまたはdescを選択 - date_sort:
ascまたはdescを選択 - start: [int] - 表示する最初の結果のインデックス番号
- size : [int] - 表示する結果の数
- text_training_status: Optional[str] - データセットのステータス(使用可能な値:trained、untrained)
- image_training_status: Optional[str] - データセットのステータス(使用可能な値:trained、untrained)
- active_status: Optional[str] - データセットのアクティブステータス(使用可能な値:archived、active
単一のドキュメントを表示
単一のドキュメントを表示するには、どのデータセットからでもエンドポイント GET /v1/gpt/datasets/{dataset_id}/documents/{document_id} を使用してください。
このエンドポイントでは、データセットIDとドキュメントIDを指定します。
以下にレスポンスの例を示します。:
{
"detail": {
"dataset_id": "7f3036cb-59b5-4046-a23f-66f2427329df",
"data": {
"idx": "6dfdbb0c-1c8d-4ba5-b137-31d099908c84",
"content": "これは役立つ情報が満載のテキストドキュメントの内容です。",
"tokens": "101.0"
},
"status": "trained",
"image_train_status": null,
"active_status": "active",
"created_at": "2024-05-24T12:21:02.715715+09:00",
"content": "idx:6dfdbb0c-1c8d-4ba5-b137-31d099908c84\n content:これは役立つ情報が満載のテキストドキュメントの内容です。\n tokens:101.0"
}
}
データセットとドキュメントの管理
データセットを作成
新しいデータセットを作成するには、エンドポイント POST /v1/gpt/datasets を使用してください。
以下にリクエストボディの例を示します。:
{
"name": "マイデータセット",
"idx_column": "id",
"is_idx_fillup_if_empty": true,
"secondary_idx_column": "slug",
"image_url_column": "image_url",
"description": "これは...に関する情報を含むデータセットです。",
"tags": "tag1, tag2, tag3",
"filterable_fields": "field1,field2,field3"
}
パラメータの説明をいたします。
- name: データセットに名前を付けて、後で簡単に識別できるようにしてください。
- idx_column: データ単位(ドキュメント)のIDを含むカラム名を指定します。指定した列がデータセットに存在しない場合、システムは自動的に列を作成しますのでご留意ください。
- is_idx_fillup_if_empty:
trueに設定すると、上記で指定したidx_columnの空の値を自動的に埋めます。falseに設定すると、空の値は埋められず、idx_columnに空の値が存在する場合はエラーが発生します。 - image_url_column: データセットに画像が含まれており、Vision API を使用したい場合は、
image_url_columnを設定してください。image_url_columnでは、データユニットの画像URLを含む列名を指定する必要があります。 - description: データセットの内容説明。
- tags: カンマで区切られたデータセットのタグリスト。例えば、社内アプリケーション専用のデータセットには
社内タグを設定できます。カスタマーサービス用のデータセットにはカスタマーサービスタグを付けることもできます。データセットには複数のタグを付けることができ、例えば [customer_service, marketing] のように設定できます。 - filterable_fields: レスポンス生成中にコンテキストをフィルタリングするために使用するカンマで区切られたフィールドのリスト。
データセットの作成に成功すると、dataset_id が取得できます。
データセットの更新または削除
データセットのメタデータを更新するには、PUT /v1/gpt/datasets/{dataset_id}エンドポイントを使用してください。
データセットを削除するには、該当のdataset_idを指定して、DELETE /v1/gpt/datasets/{dataset_id}エンドポイントを使用してください。
ドキュメント管理
複数のデータセット内およびデータセット間で効率的なドキュメント管理をサポートするエンドポイントがいくつかあります。このチュートリアルではドキュメント管理のエンドポイントを大まかに3種類に分けています。:
- ドキュメントを作成,
- ドキュメントを一括編集,
- 単一のドキュメントを編集.
以下では、それぞれのエンドポイントについて説明します。
ドキュメントを作成
特定のデータセットにドキュメントを作成するには、POST /v1/gpt/datasets/{dataset_id}/documentsを使用します。
どのデータセットに属するかを示すために、dataset_idの指定が必要です。
リクエストボディの例:
{
"documents": [
{
"key1": "value1"
},
{
"key1": "value1",
"key2": "value2"
}
],
"is_background_task": true
}
ドキュメントの下に、作成するオブジェクトのリストを提供します。各ドキュメントにはランダムなIDXが作成され、キーと値が追加されます。
パラメーター "is_background_task" は、処理をバックグラウンドで実行するかどうかを指定します。
true を設定すると、すぐに task_id を含むレスポンスが返され、ステータス(成功または失敗)を確認するためにはタスク用エンドポイントを使用する必要があります。
falseを指定すると、レスポンスにステータスが直接含まれます。小規模なバッチ処理の場合、即時のフィードバックのために false を設定することをお勧めします。
ファイルを使ってドキュメントをアップロード
ファイルを使用してドキュメントをアップロードするには、PUT /v1/gpt/datasets/{dataset_id}/file エンドポイントを使用します。
dataset_id で指定したデータセットに対応形式のファイルをアップロードすることでドキュメントを追加できます。
対応ファイル形式: PDF、CSV、JSON
ファイル形式によって、アップロードの動作が異なります:
-
PDFファイルの場合、
is_ocrパラメーターをtrueに設定することでOCRを有効にできます。これにより、画像やスキャンされたコンテンツからテキストを抽出できるようになります。is_ocrがfalseの場合、選択可能なテキストのみが抽出されます。 -
CSVおよびJSONファイルの場合、サポートされているエンコーディングは
utf-8、ascii、cp932、およびshift_jisです。
注意:新しいドキュメントが既存のドキュメントと同じIDX値を持つ場合、既存のドキュメントが上書きされます。
ドキュメントを一括編集
単一のデータセット内のドキュメントを一括編集
単一のデータセット内のドキュメントを一括更新するには、PUT /v1/gpt/datasets/{dataset_id}/documents を使用します。
以下にリクエストボディの例を示します。
{
"documents": [
{
"your_idx_column": "abc",
"key1": "value1",
"key2": "value2"
},
{
"your_idx_column": "def",
"key1": "value1",
"key2": "value2"
}
],
"is_background_task": true
}
例えば、IDX列が id のデータセットにて、ドキュメント101と102を更新したい場合、リクエストボディは以下のようになります。
{
"documents": [
{
"id": 101,
"key1": "updated value",
"key2": "updated "
},
{
"id": 102,
"key1": "value1",
"key2": "value2"
}
],
"is_background_task": true
}
key1 と key2 は、データセット内の既存のキー、または新規のキーとなる場合があります。
データセット内でドキュメントのメタデータを一括更新
PATCH /v1/gpt/datasets/{dataset_id}/documents エンドポイントを使用すると、特定のデータセット内のドキュメントのメタデータを一括更新できます。以下にリクエストボディの例を示します。:
{
"ids": [
"idx-1",
"idx-2"
],
"is_update_all": false,
"status": "trained",
"image_train_status": "trained",
"active_status": "archived"
}
is_update_all ではすべてのドキュメントを更新するかどうかを決定し、デフォルトは falseです。is_update_all パラメータが true に設定されている場合、ids パラメータは無視されます。特定のドキュメントのメタデータを更新するには、更新対象のドキュメント IDsのリストを指定してください。
以下のパラメータを使用して、更新内容を指定できます。:
- status: テキストトレーニングのステータス(値の選択肢:trained、untrained)。
- image_train_status: 画像トレーニングのステータス(値の選択肢:trained、untrained)。
- active_status: ドキュメントのステータス(値の選択肢:archived、active)。
データセット内の複数のドキュメントを削除
データセット内の複数のドキュメントを削除するには、以下のエンドポイントを使用します。
DELETE/v1/gpt/datasets/{dataset_id}/documents
リクエストボディ例:
{
"ids": [
"string"
],
"is_delete_all": false
}
データセットを指定するために dataset_id を提供する必要があります。
is_delete_all が true の場合、ids の値は無視されます。誤ってすべてのデータセットを削除しないよう、非常に注意してください。
単一のドキュメントを編集
単一のドキュメントを更新
単一のドキュメントを更新するには、以下のエンドポイントを使用します。
PUT /v1/gpt/datasets/{dataset_id}/documents/{document_id}
ヘッダーにdataset_idと document_id を指定する必要があります。リクエストボディには、更新したいキーと値を提供してください。以下は、リクエストボディの例です。
{
"data": {
"key1": "value1",
"key2": "value2"
}
}
単一のドキュメントのメタデータを更新
ドキュメントには、以下3つのメタデータがあり、これらを更新するには、PATCH /v1/gpt/datasets/{dataset_id}/documents/{document_id} を使用し、dataset_id と document_idを指定します。以下は、リクエストボディの例です。:
{
"status": "trained",
"image_train_status": "trained",
"active_status": "archived"
}
単一のドキュメントを削除
単一のドキュメントを削除するには、DELETE /v1/gpt/datasets/{dataset_id}/documents/{document_id}
を使用しdataset_idと document_id を指定します。
UIから会話履歴をドキュメントとしてトレーニングデータに追加する
新規または既存のデータセットに会話履歴をドキュメントとして追加することができます。追加されたドキュメントは、トレーニングデータとして学習されます。 この手順を実施することで、過去の会話履歴を簡単に追加し、Mairaの知識を強化することができます。
主な用途
- 応答の正確性チェック。Mairaの回答が適切かどうかを確認
- 誤った情報や不適切な表現をピックアップ
- フィードバックによる学習間違いの訂正や情報の追加
- 評価結果をMairaのトレーニングデータとして活用
メリット
- AIの回答精度が徐々に向上
ポイント
・会話履歴内の情報は自動的にデータセットには入りません。
・会話履歴内の情報をデータセットに追加し学習データとして使用する場合は、マニュアル(手動)で追加する必要があります。
・この機能は、管理者のみ操作可能です。
手順
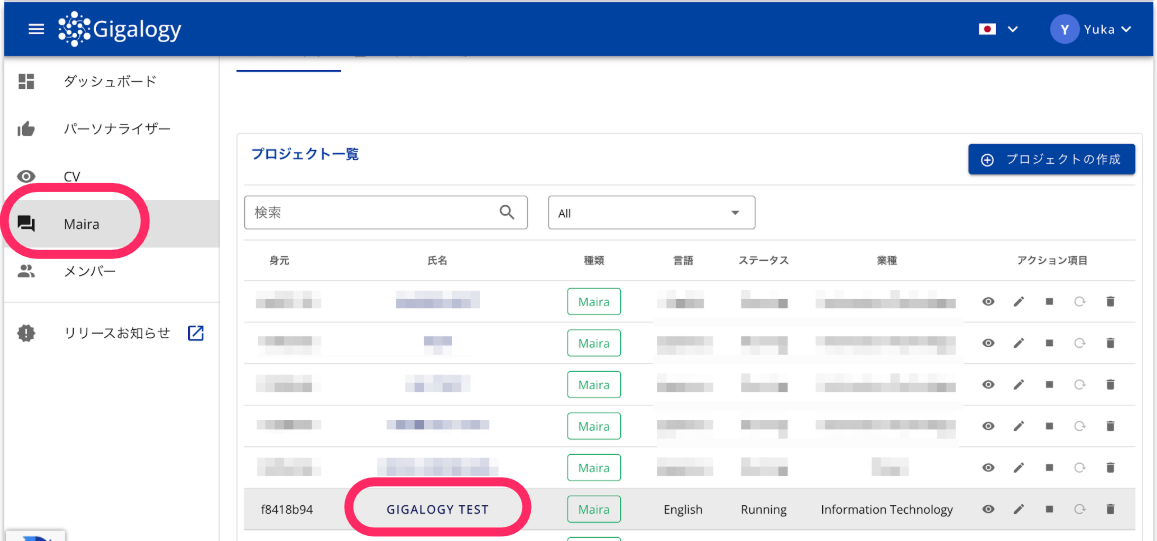
1. プロジェクトを選択する
- Mairaにログインします。
- 「プロジェクト一覧」から対象のプロジェクトをクリックします。
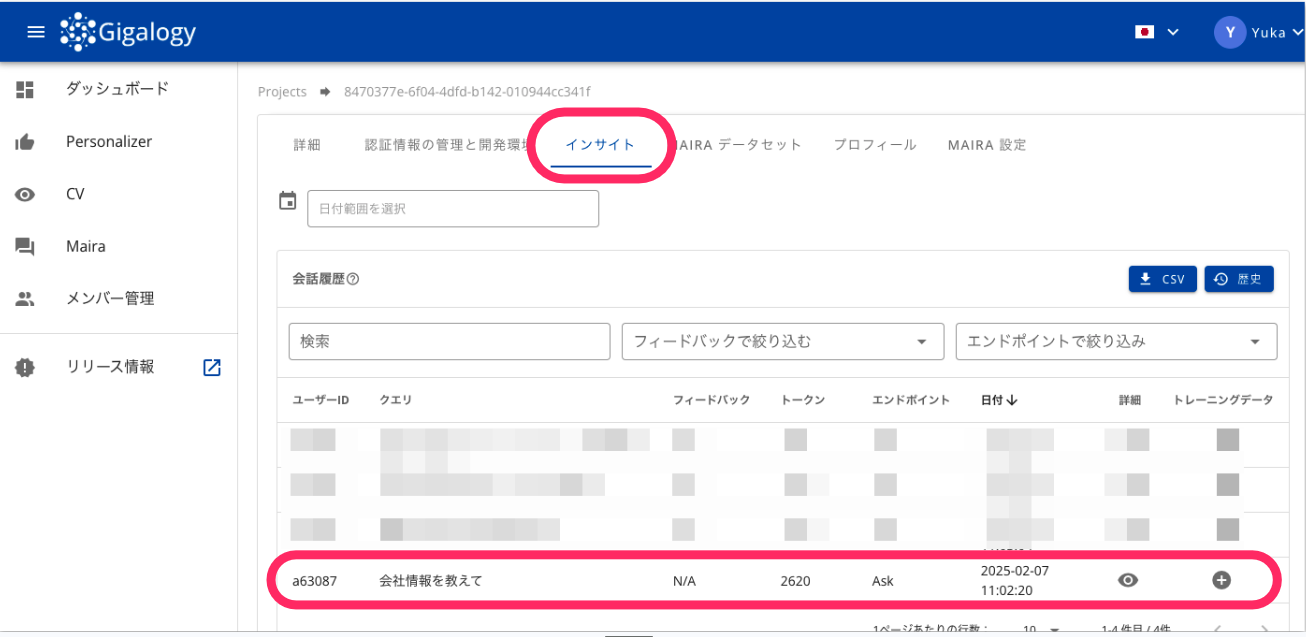
2. トレーニング会話履歴を探す
- 次に、画面上部の「インサイト」タブをクリックします。
- 「インサイト」画面で、追加したい会話履歴を見つけます。
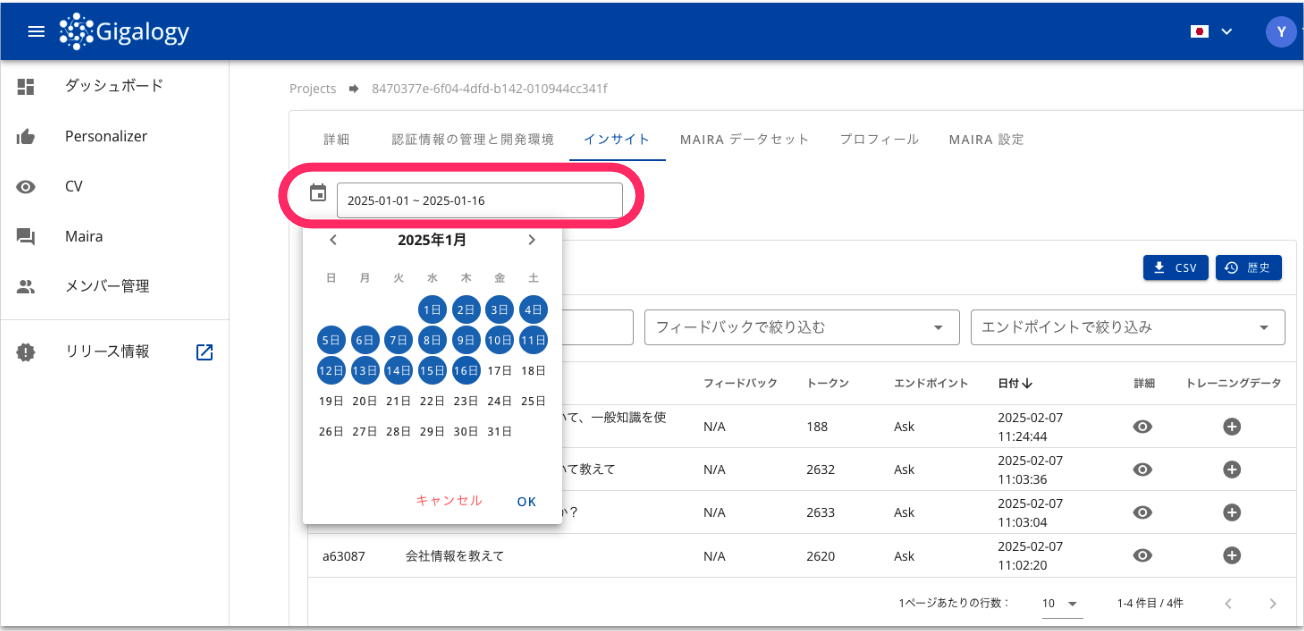
選択したい会話履歴が1週間以上前のものの場合は、画面左上のカレンダー機能を使用し、該当する会話を行なった日付を選択してください。
3. トレーニングデータに追加する
追加したい会話履歴データの右端にある[+]をクリックします。
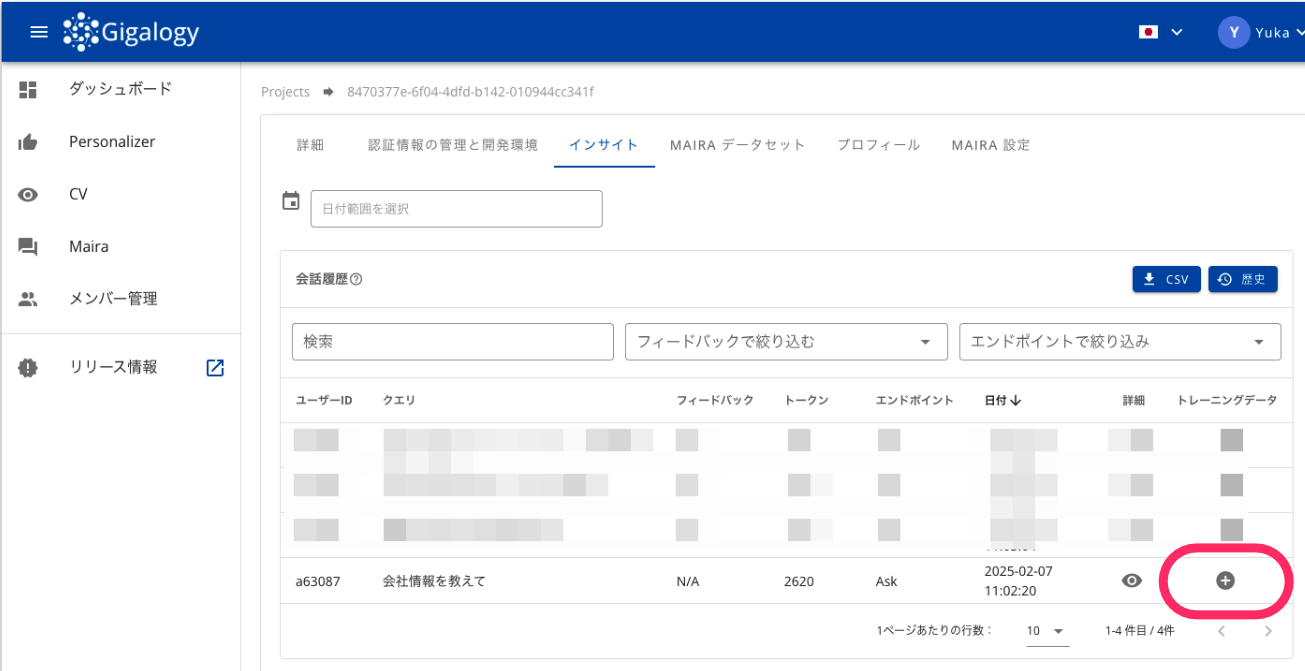
次に、トレーニングデータとして追加する方法を選択します。
方法:
- 新規データセットとして、トレーニングデータを作成する
- 既存のデータセットに、トレーニングデータをドキュメントとして追加する
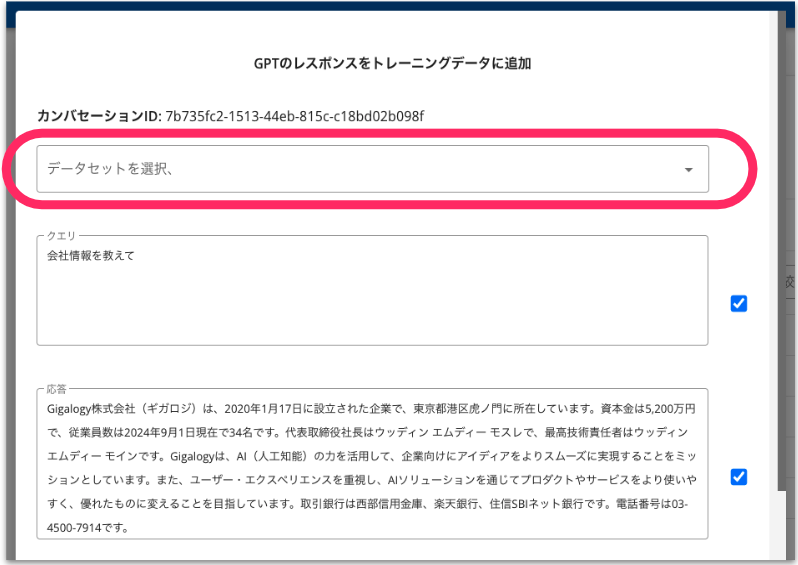
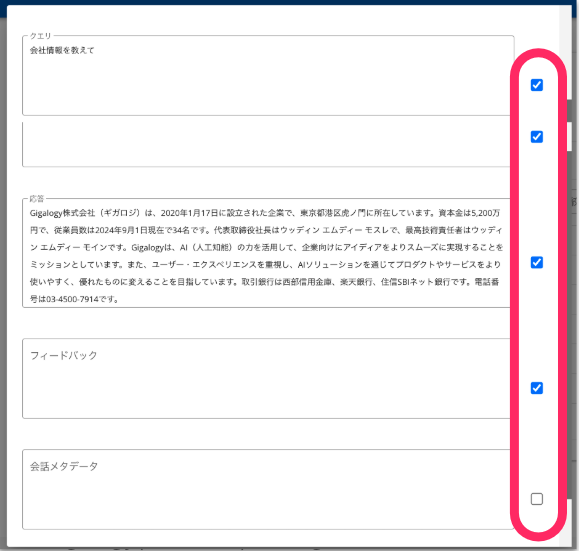
データセットに追加したい項目にチェックを入れます。各項目は内容を編集することが可能です。
- クエリ:ユーザーがMairaに質問や指示する際に使用した内容です。
- 応答:ユーザーの質問や指示に対してMairaが返した内容です。
- フィードバック:Mairaの応答に対するフィードバックです。
- 会話メタデータ:会話メタデータを設定している場合に内容が表示されます。詳しくは「Mairaの統合」チュートリアルを参照ください。
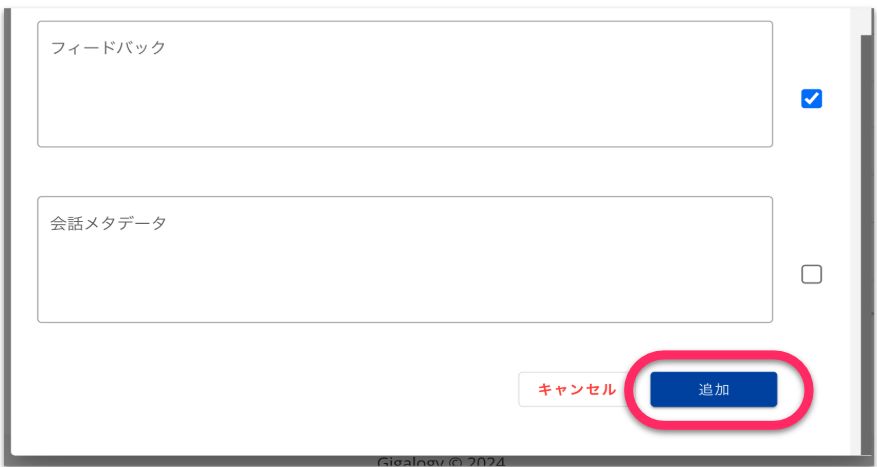
トレーニングデータに入れる内容を編集し「追加」をクリックすると、データセットに追加されます。
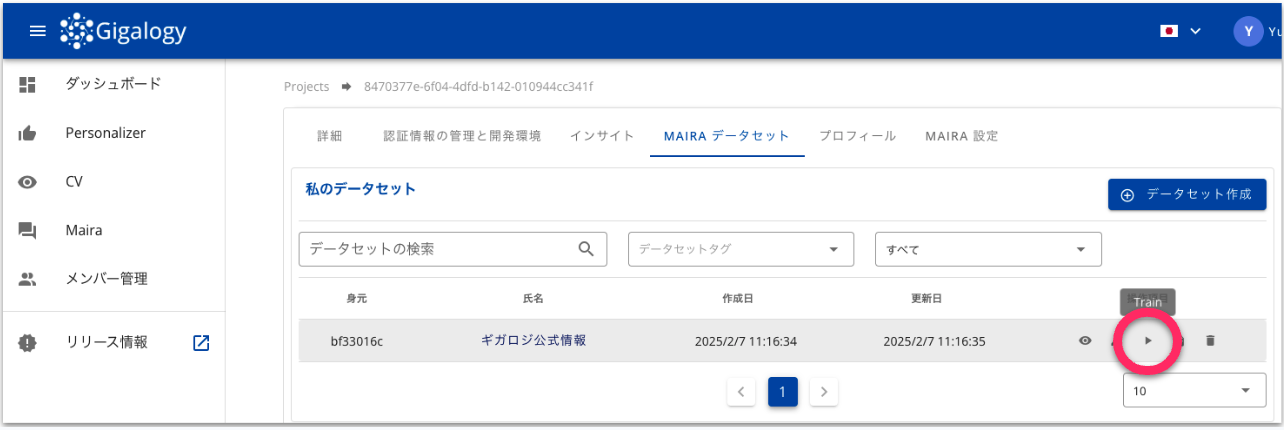
追加されたデータセットは、MAIRAデータセット画面より確認いただけます。
追加されたデータセットは、基本的に3時間に一回のバッチでトレーニングされます。 このため、トレーニングデータに入れた段階では、ドキュメントのステータスは「Untrained」となります。
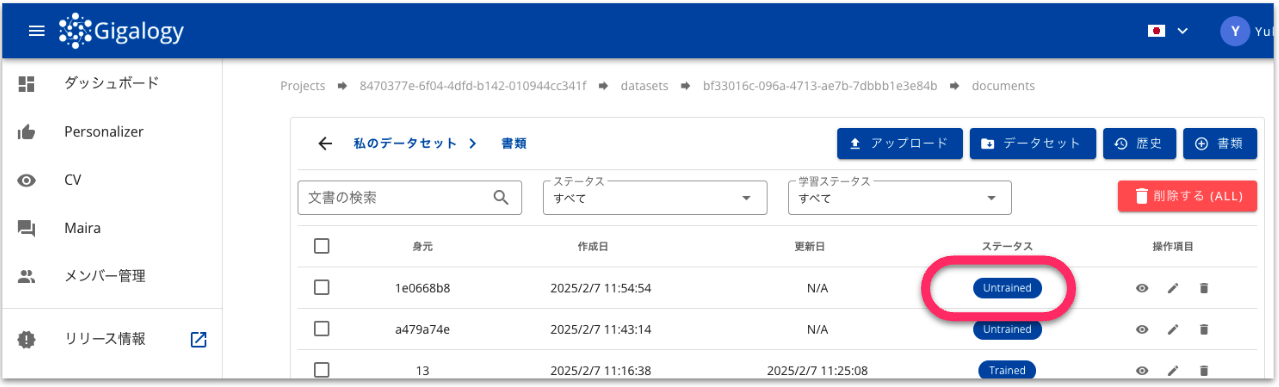
もし、即時トレーニングさせたい場合は、手動でトレーニングを行うことが可能です。 トレーニングデータが入っているデータセットの画面より「▶︎」をクリックすることでトレーニングに進めることができます。