プロフィール
GPT Profilesは、Mairaが提供する独自かつ強力な機能です。スマートアプリケーションやカスタマイズされたGPTをMairaで構築する際、この機能を使用して目的、性格、応答に関する指示、およびその他の主要な設定を定義できます。これらの設定は、プロンプトのコンテキストと共に考慮され、最適な応答を生成します。
複数のプロフィールを作成し、必要に応じて切り替えることが可能です。以下では、この機能についてさらに詳しく説明します。
Mairaを使用するには、少なくとも1つのプロフィールが必要です。また、デフォルト プロフィールを定義する必要があり、profile_idを指定せずにプロンプトを送信した場合には、このデフォルトプロフィールが適用されます。このドキュメントを読み進めることで、これらの概念がより明確になります。
新しいプロフィールを作成
新しいプロジェクトを作成した後、プロジェクトの初期設定を完了するために「セットアップ」ページに遷移します。このセットアップは3つのステップで構成されています。:
- プロフィールの設定
- データセットのアップロード
- データセットのトレーニング
このセクションでは、最初のステップであるプロフィールの設定についてご説明いたします。
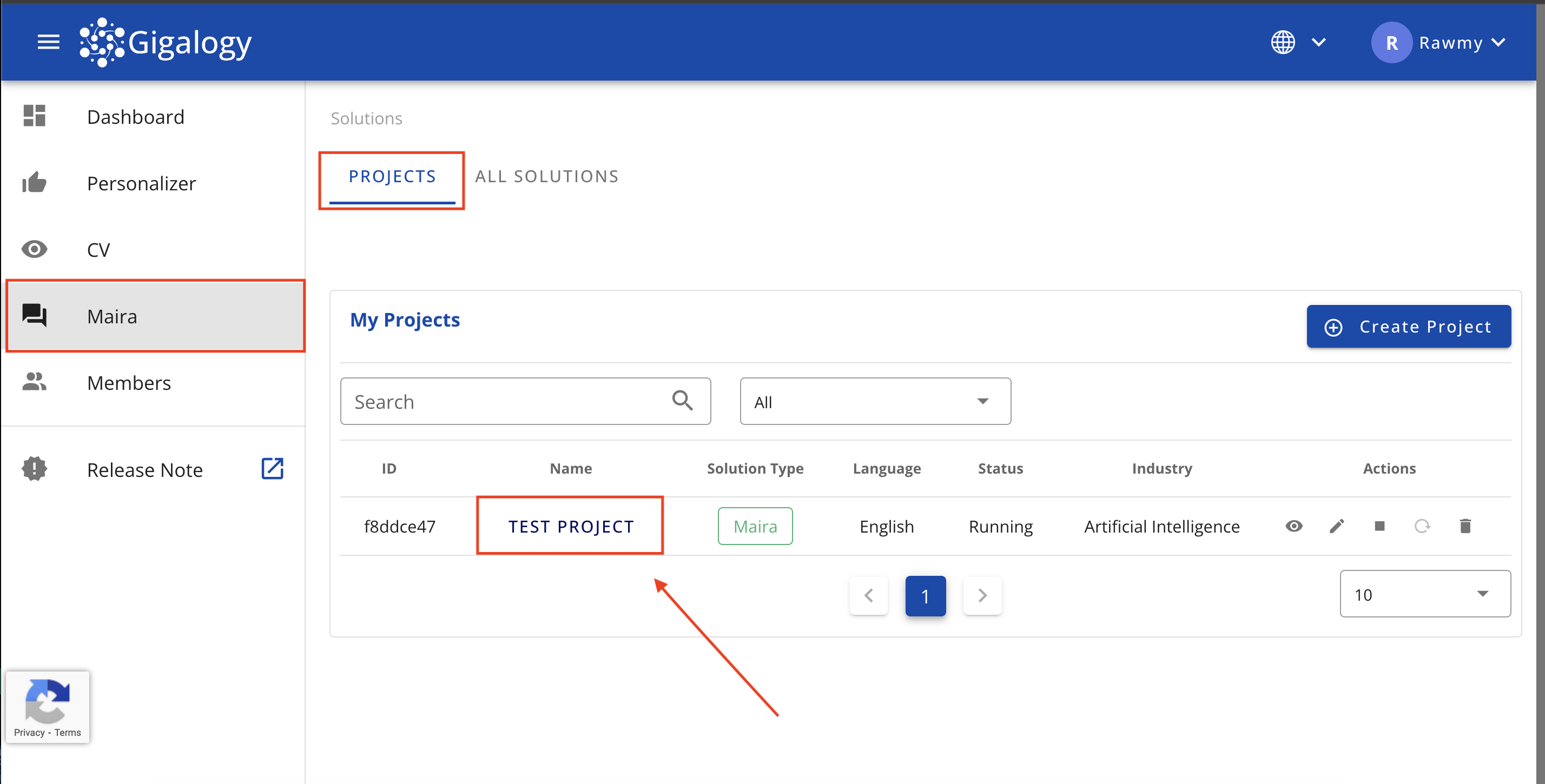
まず、Mairaソリューションページに移動し、プロジェクトをクリックしてください。
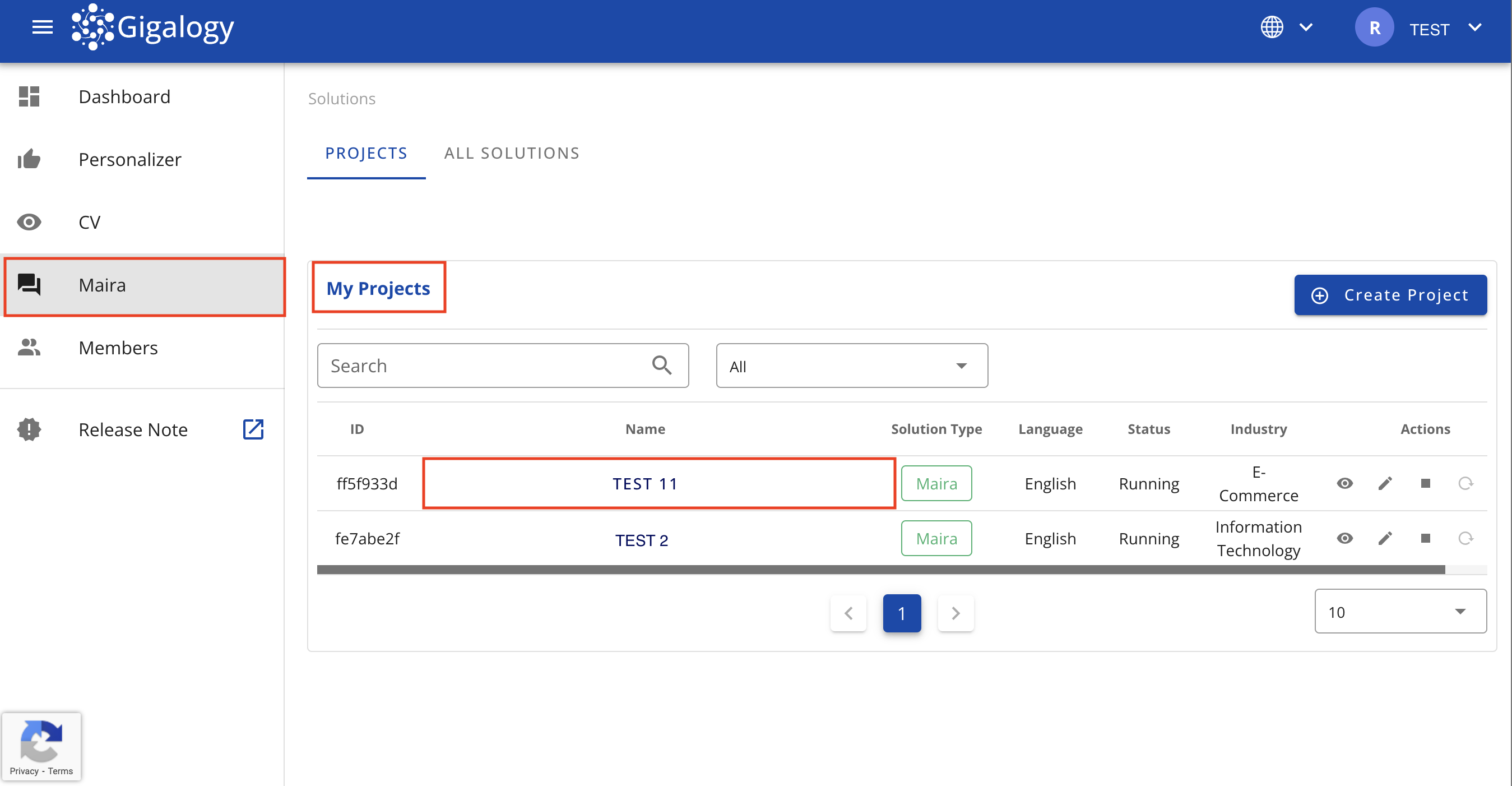
以下画像の「セットアップ」ステップに移動し、最初の「プロフィール」を作成します。各パラメータの説明は以下に記載されています。
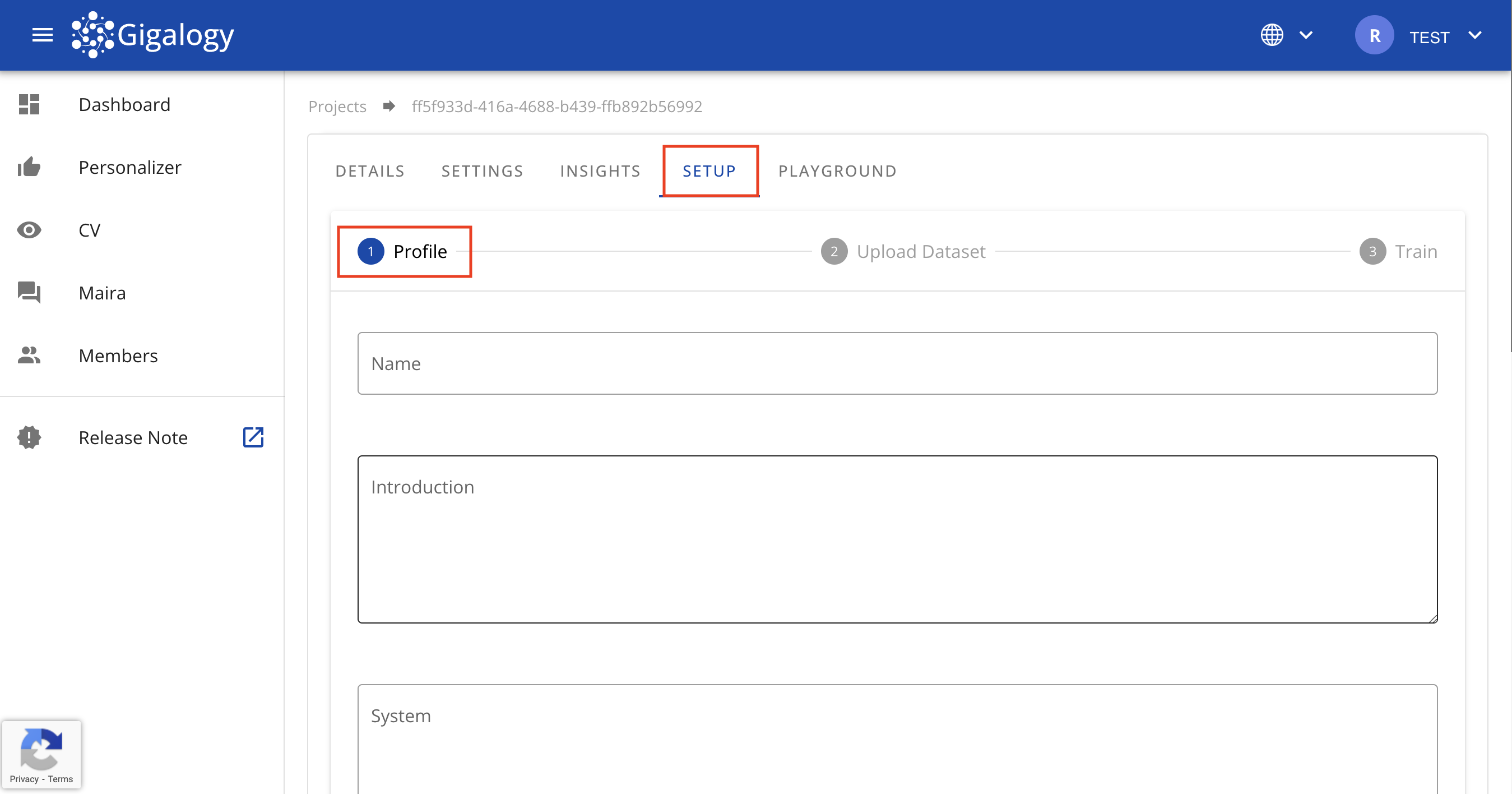
-
氏名: 管理者がその目的を把握しやすいように、プロフィールに名前を付けてください。
-
応答方針: AIが応答を生成する際の具体的な指示やルールを設定できるMairaの機能です。
- 応答方針例: 常に簡潔で丁寧な言葉を使用し、質問に対して的確に答える。各応答の後に3つのフォローアップ質問をする。答えがわからない場合は申し訳ございませんと言い、適当な回答を生成しないこと。
-
システム: AIのモードやペルソナを設定するために設計された大規模言語モデル(LLM)の機能です。
- System例: あなたはフィットネスコーチであり、個々の目標やフィットネスレベルに基づいて、パーソナライズされたトレーニングプランや栄養アドバイスを提供します。
-
指示: このセクションでは、エンドユーザーがこの特定のプロファイルとどのようにやり取りすべきかを明確に示します。これらの指示は、ユーザーがプロファイルの範囲、機能、制限を理解するのに役立ち、より効率的で関連性の高いやり取りを可能にします。
- 一般的なガイドライン:
- このプロファイルで対応可能な質問やリクエストの種類を明確に記載する。
- 対応範囲外の制限事項やトピックを指定する。
- プロファイルで利用可能なデータセットや機能に合わせて指示を調整する。
- 任意で、最も正確な回答を得るためのベストプラクティスやヒントを含めてもよい。
- 例:
- 「製品の機能、トラブルシューティングの手順、アカウント管理について質問できます。」
- 「製品の推奨や基本的な質問に回答できます。請求や機密性の高いアカウント問題については、メールでサポートにお問い合わせください。」
- 「このチャットボットは人事関連の相談専用です。個人の医療情報は送信しないでください。」
- 「フィットネスのルーティン、栄養アドバイス、一般的な健康管理のヒントについて質問できます。緊急の医療事態の場合は、医療専門家にご相談ください。」
- Note: 各プロファイルの目的や利用可能なデータに応じて"指示"内容は設定できます。明確な指示を提供することで、ユーザー体験が向上し、期待値を適切に設定できます。
- 一般的なガイドライン:
-
モデル: 必要に応じて使用したいGPTモデルを選択できます。モデルを選ぶ際には、目的や推定トークン数を考慮してください。これによりコストに大きな影響を与える可能性があります。OpenAIのモデルについては、こちらのページで詳しく知ることができます。この設定は、
search_max_token(モデルに送信されるデータに割り当てられるトークン数)およびcompletion_token(返信に割り当てられるトークン数)というパラメータに影響を与えます。intro、system、およびqueryのトークンコストは、search_max_tokenとcompletion_tokenにおけるトークンサイズの割り当てには含まれていないことに注意してください。選択したモデルのCONTEXT WINDOWは、トークン割り当ての合計をカバーします。すなわち、_CONTEXT WINDOW≥search_max_token+completion_token+intro+system+query_です。 -
温度: 温度の範囲は0から2の間です。低いtemperature(より0に近い)ほど出力はより決定的で焦点を絞ったものになり、モデルはトレーニングデータに基づいてより確率の高い単語を選択します。一方、高いtemperature(より2に近い)ほど、出力はより偶然的でクリエイティブなものになり、幅広い単語の選択肢が得られます。
-
核サンプリング: temperatureを用いたサンプリングの代替手法であり、核サンプリングとも呼ばれています。この手法ではモデルがtop_pに入る値の範囲内の確率質量を持つトークンの結果を考慮します。つまり、値が0.1の場合は上位10%の確率質量を構成するトークンのみが考慮されることを意味します。
- 核サンプリング = 0.9の場合、モデルは次の単語を選ぶ際に、確率質量の上位90%のみを考慮し、確率質量の低い選択肢は除外します。
- 核サンプリングの値が低いほど出力はより決定的になり、高いほどより多様になります。
-
頻度ペナルティ: 出力においてモデルが同じトークンを繰り返す可能性を減少させるパラメータです。よく使われるトークンにはペナルティが与えられ、より多様な単語の選択を促します。
- 頻度ペナルティ = 0.0の場合, ペナルティはなく、モデルはトークンを自由に繰り返すことができます。
- 頻度ペナルティの値が高くなると、モデルが言葉を繰り返す可能性が低くなり、出力のバリエーションが増えます。
-
プレゼンスペナルティ: Default=0.0, ge=0.0, le=2.0. すでに出力された内容に含まれたトークンにペナルティを課すことで、モデルが新しいトークンを導入することを促すパラメータです。これにより、モデルはあまり使われていない単語や新しい単語を使用するようになります。
-
停止する: stopでは、モデルがテキスト(トークン)の生成を停止する条件を指定します。例えば["world", "coding"]のような文字列(最大4つ)のリストが指定された場合、モデルがこれらのいずれかに遭遇すると、テキストの生成を停止します。 例として、モデルが
hello worldを生成した場合、worldがstopシーケンスに含まれるため、helloまでで生成を終了し結果を返します。また、モデルがI love codingを生成した場合、最後のトークンcodingがstopシーケンスに含まれるため、新たなトークンの生成を終了しI loveを返します。stopシーケンスは任意のパラメータで、デフォルトは空のリストです。そのため、指定がない場合は応答が自然に終了するまでトークンの生成を続けます。 -
クセスタグ: アクセスタグは、ゲストユーザーがアクセスできるプロファイルを制限するために使用されます。ゲストユーザーの追加方法については、ゲストユーザー管理チュートリアルをご覧ください。
-
search max token: モデルに送信されるコンテキスト用のトークン数を示します。デフォルト値は動的で、各モデルごとにそれぞれデフォルト設定があります。検索最大トークンが0の場合、GAIPは内部データベースを一切参照しません。
-
Completion Tokens: Default=2000,例=2500. 応答に割り当てられるトークンの数です。
-
Chat History Length: GPTにコンテキストとして送信するために保持する直前の会話の数です。
-
Is Personalizer Only: プロフィールがパーソナライザー専用かどうか。デフォルト値は
Falseです。
詳しくはこちら
このパラメータは、Mairaに送信されるコンテキストに影響します。"is_personalizer_only": true の場合、データセットエンドポイントを通じてアップロードされたすべてのデータセットは考慮されず、コンテキストは商品カタログに制限されます。"is_personalizer_only": falseの場合は、Mairaデータセットとパーソナライザーの商品カタログの両方がコンテキストとして使用されます。
-
自動評価: 各会話の後に評価を自動的に実行するかどうかを決めます。(評価については、Mairaの評価チュートリアルで詳しく説明します。)
-
search_mode: オプション。- 検索の種類を指定します。使用可能なバリューは「context」(コンテキスト)、「full_text」(全文検索)、または「hybrid」(ハイブリッド)です。
- コンテキストモード: AIによるコンテキスト検索を使用し、意味を理解してデータセットから関連するコンテンツを見つけます。
- 全文検索モード: キーワードベースの検索を使用して、データセットから関連するコンテンツを見つけます。
- ハイブリッドモード: クエリに基づいて、コンテキスト検索を使用するかどうかを自動的に判断します。
注意: v1/maira/ask の is_keyword_enabled は、コンテキスト検索時のみ「キーワードブースト」として機能します。有効にすると、ベクトル類似度検索にキーワードフィルタリングが追加されますが、「full_text」検索モードでは影響しません。
-
データセットタグ:: コンテキスト構築に含めるべきデータセットのタグ、または除外するべきデータセットのタグを入力するパラメーターです。
- Include: コンテキスト生成において含めるタグ。
- Exclude: コンテキスト生成において除外するタグ。
初期設定が完了すると、「プロフィール」テーブルにすべてのプロフィールのリストが表示されます。
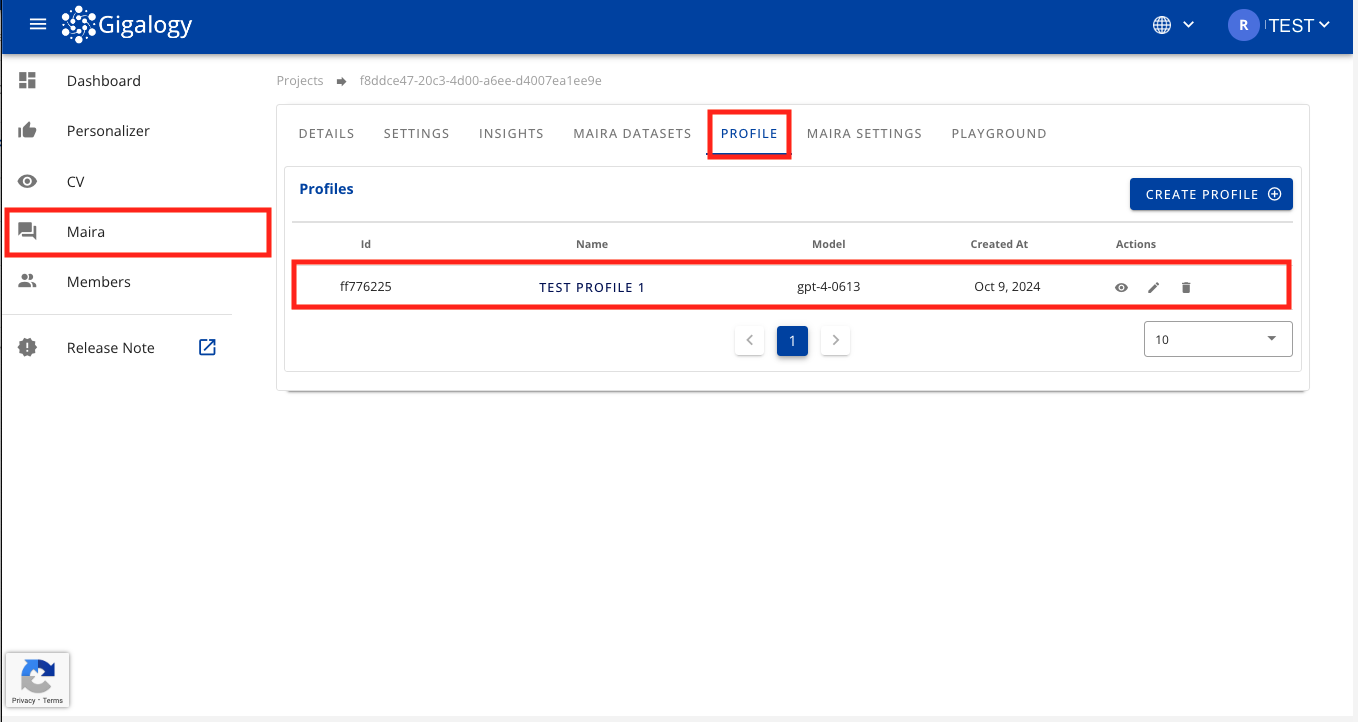
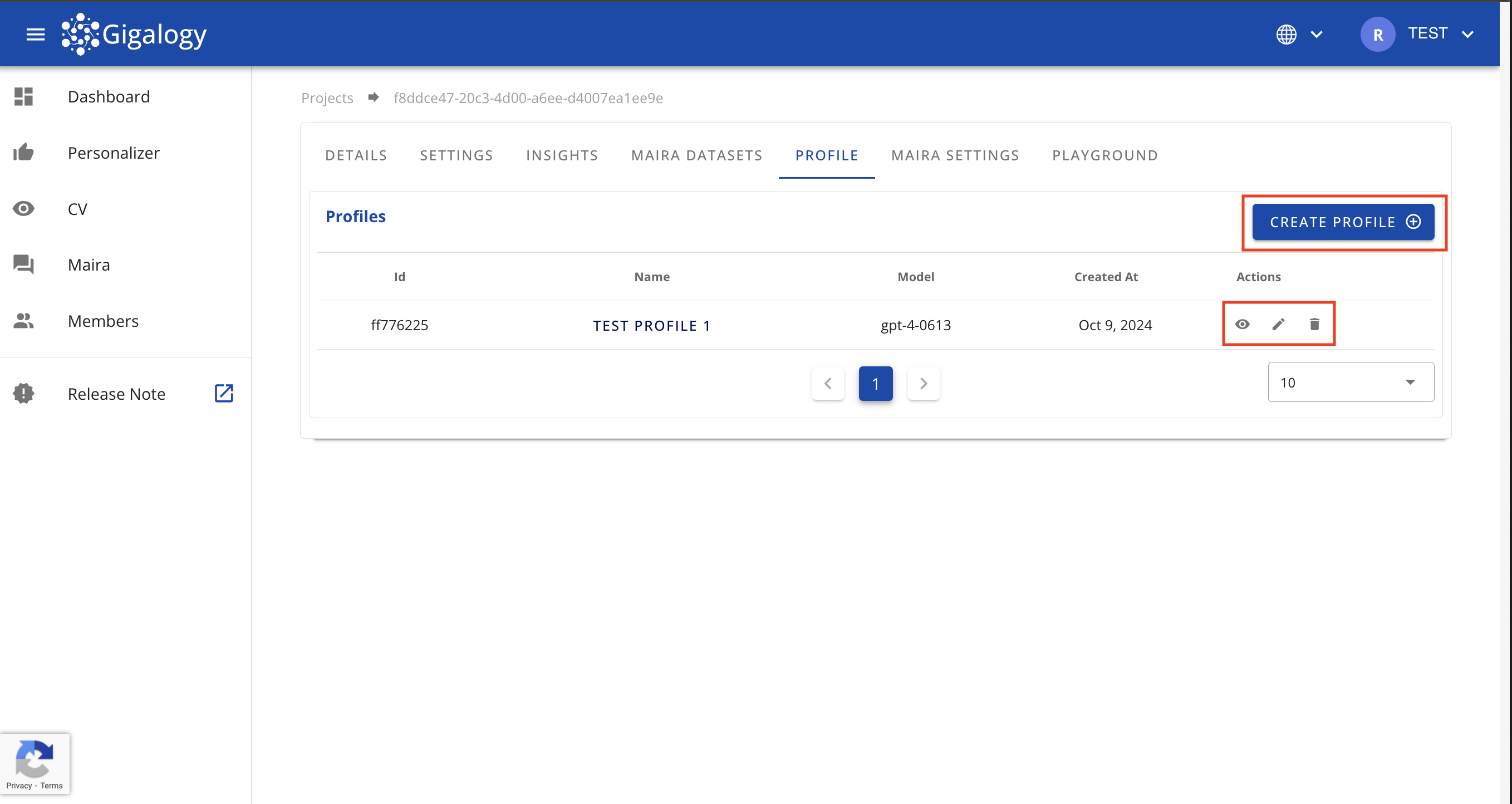
このページからは、「プロフィール作成」ボタンをクリックして新しいプロフィールを作成したり、アクション項目のボタンを使って既存のプロフィールを編集または削除したりできます。
新しいプロフィールを作成するには、エンドポイントPOST /v1/gpt/profilesを使用します。以下サンプルリクエストです。:
{
"name": "プロフィールには、後で簡単に識別できるような、意味のある名前を付けてください。",
"intro": "GPTの目的や役割、望ましい出力形式について説明してください。",
"system": "GPTのパーソナリティを定義してください。",
"instructions": "Provide instructions to the user.",
"model": "gpt-3.5-turbo-0125",
"temperature": 0,
"top_p": 1,
"frequency_penalty": 0,
"presence_penalty": 0,
"stop": [
"AI:",
"Human:"
],
"access_tags": [
"ML",
"AI",
"Business",
"HR"
],
"response_format": "json_object",
"search_max_token": 2500,
"completion_token": 2500,
"vision_settings": {
"resolution": "lowまたはhigh。デフォルトはlowです。",
"is_image_context_enabled": true
},
"chat_history_length": 3,
"chat_history_length": 3,
"is_personalizer_only": false,
"dataset_tags": {
"includes": [
"tag1",
"tag2"
],
"excludes": [
"tag1",
"tag2"
]
},
"is_auto_evaluation": false,
"is_lang_auto_detect": true
"search_mode": "context",
"dataset_languages": [
"en",
"ja"
]
}
各パラメータについて詳しく見ていきましょう。
-
name: str - 管理者がその目的を把握しやすいように、プロフィールに名前を付けてください。
-
intro: str - AIが応答を生成する際の具体的な指示やルールを設定できるMairaの機能です。
- intro例: 常に簡潔で丁寧な言葉を使用し、質問に対して的確に答える。各応答の後に3つのフォローアップ質問をする。答えがわからない場合は申し訳ございませんと言い、適当な回答を生成しないこと。
-
system: str - AIのモードやペルソナを設定するために設計された大規模言語モデル(LLM)の機能です。
- System例: あなたはフィットネスコーチであり、個々の目標やフィットネスレベルに基づいて、パーソナライズされたトレーニングプランや栄養アドバイスを提供します。
-
instructions: (任意) - このセクションでは、エンドユーザーがこの特定のプロファイルとどのようにやり取りすべきかを明確に示します。これらの指示は、ユーザーがプロファイルの範囲、機能、制限を理解するのに役立ち、より効率的で関連性の高いやり取りを可能にします。
- 一般的なガイドライン:
- このプロファイルで対応可能な質問やリクエストの種類を明確に記載する。
- 対応範囲外の制限事項やトピックを指定する。
- プロファイルで利用可能なデータセットや機能に合わせて指示を調整する。
- 任意で、最も正確な回答を得るためのベストプラクティスやヒントを含めてもよい。
- 例:
- 「製品の機能、トラブルシューティングの手順、アカウント管理について質問できます。」
- 「製品の推奨や基本的な質問に回答できます。請求や機密性の高いアカウント問題については、メールでサポートにお問い合わせください。」
- 「このチャットボットは人事関連の相談専用です。個人の医療情報は送信しないでください。」
- 「フィットネスのルーティン、栄養アドバイス、一般的な健康管理のヒントについて質問できます。緊急の医療事態の場合は、医療専門家にご相談ください。」
- Note: 各プロファイルの目的や利用可能なデータに応じて"instruction"内容は設定できます。明確な指示を提供することで、ユーザー体験が向上し、期待値を適切に設定できます。
- 一般的なガイドライン:
-
model: str - 必要に応じて使用したいGPTモデルを選択できます。モデルを選ぶ際には、目的や推定トークン数を考慮してください。これによりコストに大きな影響を与える可能性があります。OpenAIのモデルについては、こちらのページで詳しく知ることができます。この設定は、
search_max_token(モデルに送信されるデータに割り当てられるトークン数)およびcompletion_token(返信に割り当てられるトークン数)というパラメータに影響を与えます。intro、system、およびqueryのトークンコストは、search_max_tokenとcompletion_tokenにおけるトークンサイズの割り当てには含まれていないことに注意してください。選択したモデルのCONTEXT WINDOWは、トークン割り当ての合計をカバーします。すなわち、CONTEXT WINDOW≥search_max_token+completion_token+intro+system+queryです。- モデルを選択します。利用可能な値は次のとおりです。
gpt-3.5-turbo-0125,gpt-3.5-turbo-0613,gpt-3.5-turbo-instruct,gpt-3.5-turbo-16k-0613,gpt-3.5-turbo-1106,gpt-4-0613,gpt-4-1106-preview,gpt-4-0125-preview,gpt-4-turbo-2024-04-09,gpt-4o-2024-05-13,gpt-4-vision-preview,gpt-4o-mini,gpt-4o-mini-2024-07-18,gpt-4o-2024-08-06
- モデルを選択します。利用可能な値は次のとおりです。
-
temperature: Optional[float] - Default=0.0、ge=0.0、le=2.0。低いtemperature(より0に近い)ほど出力はより決定的で焦点を絞ったものになり、モデルはトレーニングデータに基づいてより確率の高い単語を選択します。一方、高いtemperature(より2に近い)ほど、出力はより偶然的でクリエイティブなものになり、幅広い単語の選択肢が得られます。
-
top_p: Optional[float] - Default=1.0, ge=0.0, le=1.0. temperatureを用いたサンプリングの代替手法であり、核サンプリングとも呼ばれています。この手法ではモデルがtop_pに入る値の範囲内の確率質量を持つトークンの結果を考慮します。つまり、値が0.1の場合は上位10%の確率質量を構成するトークンのみが考慮されることを意味します。
- top_p = 0.9の場合、モデルは次の単語を選ぶ際に、確率質量の上位90%のみを考慮し、確率質量の低い選択肢は除外します。
- top_pの値が低いほど出力はより決定的になり、高いほどより多様になります。
-
frequency_penalty: Optional[float] - Default=0.0, ge=0.0, le=2.0. 出力においてモデルが同じトークンを繰り返す可能性を減少させるパラメータです。よく使われるトークンにはペナルティが与えられ、より多様な単語の選択を促します。
- frequency_penalty = 0.0の場合, ペナルティはなく、モデルはトークンを自由に繰り返すことができます。
- frequency_penaltyの値が高くなると、モデルが言葉を繰り返す可能性が低くなり、出力のバリエーションが増えます。
-
presence_penalty: Optional[float] - Default=0.0, ge=0.0, le=2.0. すでに出力された内容に含まれたトークンにペナルティを課すことで、モデルが新しいトークンを導入することを促すパラメータです。これにより、モデルはあまり使われていない単語や新しい単語を使用するようになります。
-
Stop: stopでは、モデルがテキスト(トークン)の生成を停止する条件を指定します。例えば["world", "coding"]のような文字列(最大4つ)のリストが指定された場合、モデルがこれらのいずれかに遭遇すると、テキストの生成を停止します。 例として、モデルが
hello worldを生成した場合、worldがstopシーケンスに含まれるため、helloまでで生成を終了し結果を返します。また、モデルがI love codingを生成した場合、最後のトークンcodingがstopシーケンスに含まれるため、新たなトークンの生成を終了しI loveを返します。stopシーケンスは任意のパラメータで、デフォルトは空のリストです。そのため、指定がない場合は応答が自然に終了するまでトークンの生成を続けます。 -
access_tags: アクセスタグは、ゲストユーザーがアクセスできるプロファイルを制限するために使用されます。ゲストユーザーの追加方法については、ゲストユーザー管理チュートリアルをご覧ください。
-
response_format: Optional[str] - 応答形式は、
json_formatとtextの2種類です。json_formatを選んだ場合、introやsystemに"json"という単語を含める必要があります。 -
search_max_token: Optional[int] - モデルに送信されるコンテキスト用のトークン数を示します。デフォルト値は動的で、各モデルごとにそれぞれデフォルト設定があります。search max tokenが0の場合、GAIPは内部データベースを一切参照しません。
-
completion_token: Optional[int] - Default=2000,例=2500. 応答に割り当てられるトークンの数です。
-
vision_settings: Optional[Dict] - 視覚モデルに必須です。
- vision_settings.resolution: 解像度(resolution)が
highの場合、コストは高くなりますが、結果の精度が向上します。lowの場合はその逆です。 - vision_settings.is_image_context_enabled:
trueは画像をコンテキストとして、テキストコンテキストと一緒にLLMに送信することを意味します。falseは、テキストコンテキストまたはリファレンスのみが使用されることを意味します。
- vision_settings.resolution: 解像度(resolution)が
-
chat_history_length: Optional[int] - GPTにコンテキストとして送信するために保持する直前の会話の数です。
-
is_personalizer_only: Optional[bool] - プロフィールがパーソナライザー専用かどうか。デフォルト値は
Falseです。詳しくはこちら
このパラメータは、Mairaに送信されるコンテキストに影響します。"is_personalizer_only": trueの場合、データセットエンドポイントを通じてアップロードされたすべてのデータセットは考慮されず、コンテキストは商品カタログに制限されます。"is_personalizer_only": falseの場合は、Mairaデータセットとパーソナライザーの商品カタログの両方がコンテキストとして使用されます。
-
search_mode: オプション。- 検索の種類を指定します。使用可能なバリューは「context」(コンテキスト)、「full_text」(全文検索)、または「hybrid」(ハイブリッド)です。
- コンテキストモード: AIによるコンテキスト検索を使用し、意味を理解してデータセットから関連するコンテンツを見つけます。
- 全文検索モード: キーワードベースの検索を使用して、データセットから関連するコンテンツを見つけます。
- ハイブリッドモード: クエリに基づいて、コンテキスト検索を使用するかどうかを自動的に判断します。
注意: v1/maira/ask の is_keyword_enabled は、コンテキスト検索時のみ「キーワードブースト」として機能します。有効にすると、ベクトル類似度検索にキーワードフィルタリングが追加されますが、「full_text」検索モードでは影響しません。
-
dataset_tags: Optional[Dict] - コンテキスト構築に含めるべきデータセットタグ、または除外するべきデータセットタグを入力するパラメーターです。タグが提供されない場合は、すべてのデータセットがコンテキスト構築の対象とされます。(データセットにタグを追加する方法に関しては、"データセット管理" チュートリアルに説明がございます。)
- dataset_tags.include: Optional[list[str]] - コンテキスト生成において含めるタグ。これらのタグに該当しないデータセットは全て除外されます。
- dataset_tags.exclude: Optional[list[str]] - コンテキスト生成において除外するタグ。これらのタグに該当しないデータセットは全て含まれます。
-
is_auto_evaluation: Optional[bool] - 各会話の後に評価を自動的に実行するかどうか(評価については、Mairaの評価チュートリアルで詳しく説明します)。評価はリソースを多く消費することにご留意ください。また、評価は別のエンドポイントを通じて手動で実行できます(評価のチュートリアルで解説しています)
-
is_lang_auto_detect: Optional[bool] - デフォルト値は
true。falseに設定すると、クエリからの自動言語検出が無効になります。- 機能: クエリの言語を検出し、AIモデルに同じ言語で応答させることで、常に期待される言語での応答を保証します。
- 注意: プロファイル内の
is_lang_auto_detectと、/v1/maira/askリクエストボディ内のlanguageフィールドの両方が使用されている場合、is_lang_auto_detectが優先されます。 - 例: クエリが英語で、プロファイルで
is_lang_auto_detect=trueに設定されており、リクエストボディでlanguage=jaが指定されている場合でも、応答は英語(検出されたクエリ言語)になります。
リクエストボディの例
以下にリクエストボディの例を示します。このボディを使用してプロフィールにアクセスし、テスト用のMairaプロフィールを作成できます。(以下、必須パラメータのみ表示)
{
"name": "最初のテスト用プロフィール",
"intro": "簡潔で客観的に、わかりやすく丁寧にお答えください。
",
"system": "あなたは私の仕事をサポートするためのボットです。",
"model": "gpt-4o-mini-2024-07-18",
"temperature": 0,
"top_p": 1,
"frequency_penalty": 0,
"presence_penalty": 0,
"stop": [
"Human:"
],
"search_max_token": 2500,
"completion_token": 2500,
"vision_settings": {},
"chat_history_length": 3,
"is_personalizer_only": false,
"dataset_tags": {
"includes": [],
"excludes": []
}
}
正常な応答は次のような形です。:
{
"detail": {
"response": "GPTプロフィールが正常に作成されました。",
"profile_id": "cfe76e28-bef9-45c8-bf5b-1f4b0117b176",
"name": "最初のテスト用プロフィール"
}
}
profile_idはレスポンスに含まれています。
既存のプロフィールを表示
すべてのプロフィールを取得
プロジェクトのすべての既存プロフィールを表示するには、プロジェクトの「プロフィール」タブに移動してください。「プロフィール」タブ内で、すべてのプロフィールのリストを確認できます。
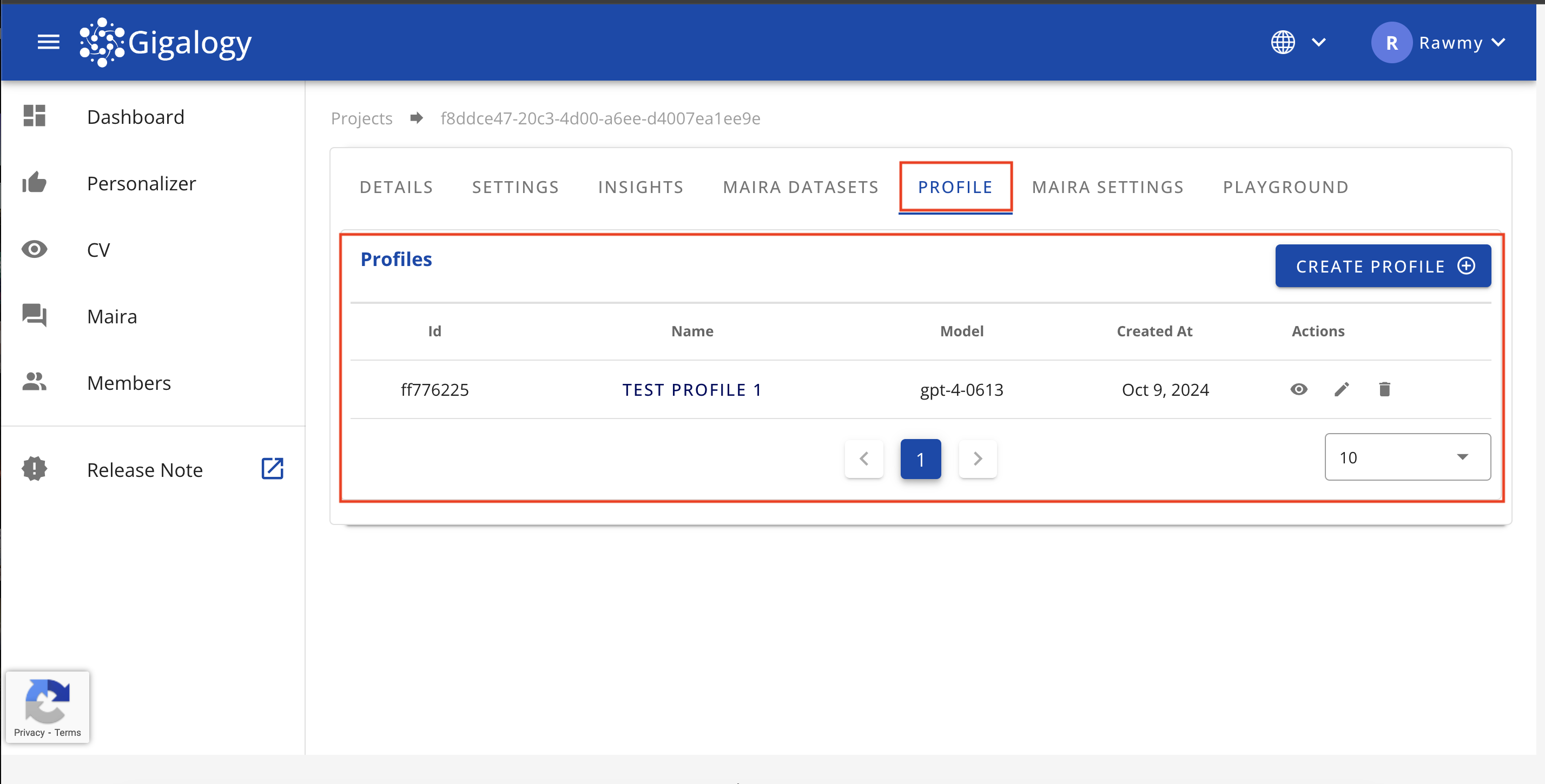
すべてのプロフィールを取得するには、GET /v1/gpt/profilesを使用します。以下のパラメータが必要です:
- start: Optional[int] - プロフィール取得の開始インデックス (デフォルト:0、最小値:0)
- size: Optional[int] - 取得するプロフィールの数(デフォルト:10、最小値:1)
レスポンスにはプロフィールのメタデータが含まれています。
1つのプロフィールの詳細を取得
既存のプロフィールの詳細を確認するには、プロジェクトのプロフィール」タブに移動し、目のアイコンをクリックしてください。プロフィールの詳細が表示されます。
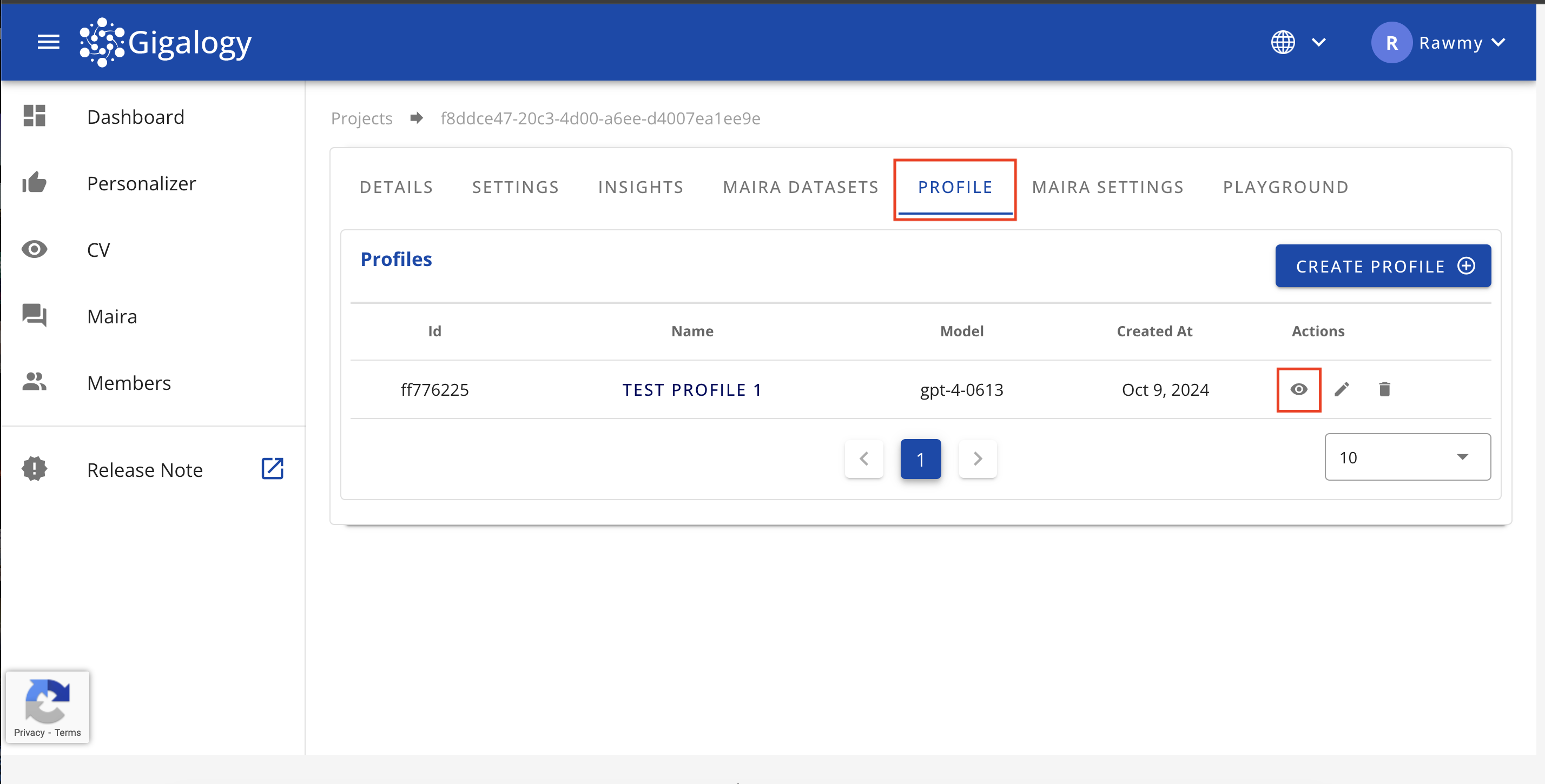
特定のプロフィールの詳細を表示するには、GET /v1/gpt/profiles/{profile_id}を使用してください。
この際、profile_idが唯一のパラメータとなります。
レスポンスには指定されたプロフィールの詳細がすべて含まれます。
プロフィールの更新
既存のプロフィールを更新するには、プロジェクトの「プロフィール」タブに移動し、鉛筆のアイコンをクリックしてください。モーダルが開き、プロフィールの詳細を編集できます。
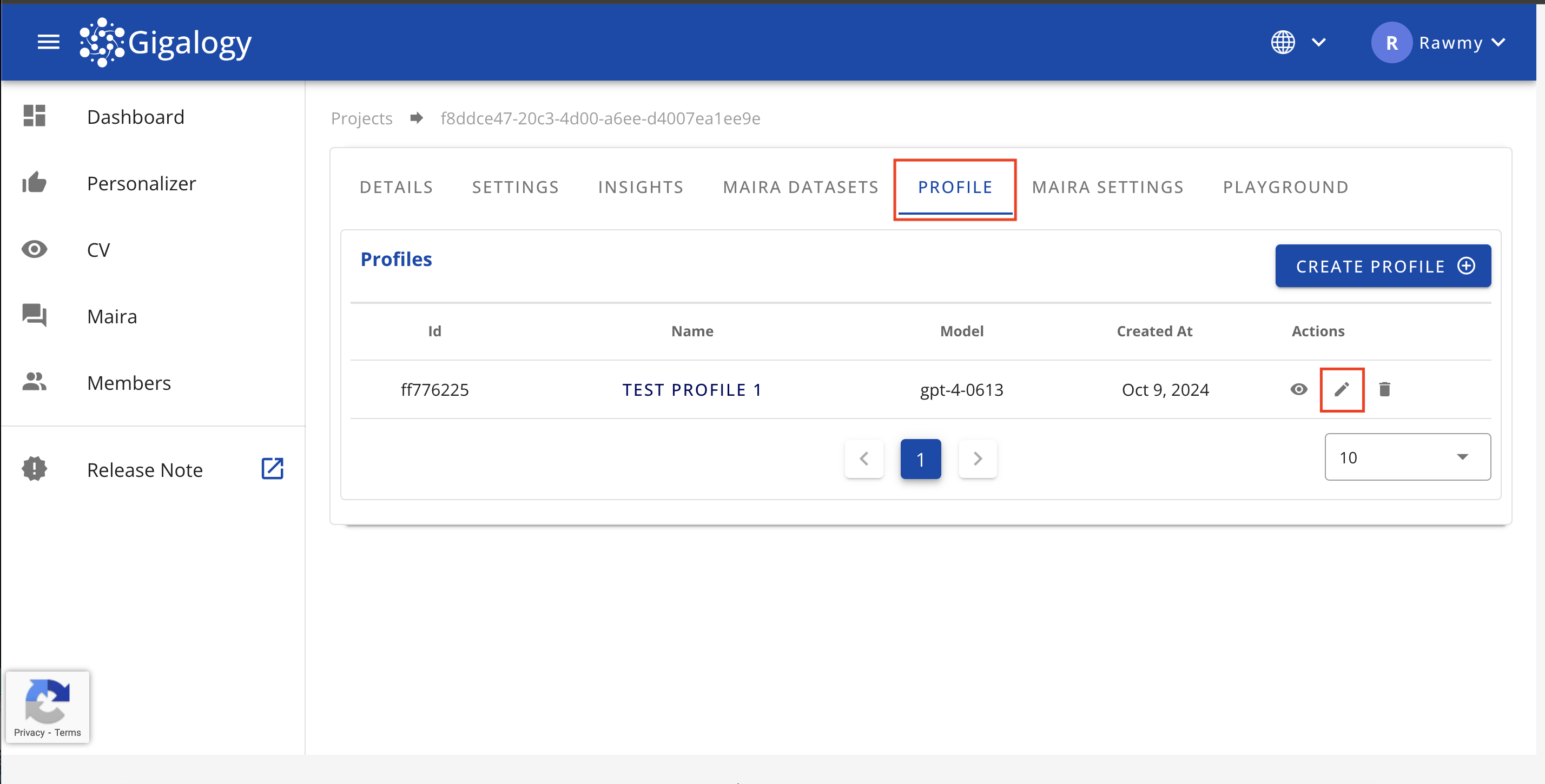
更新が完了したら、「アップデート」ボタンをクリックして変更を確定し、モーダルを閉じてください。
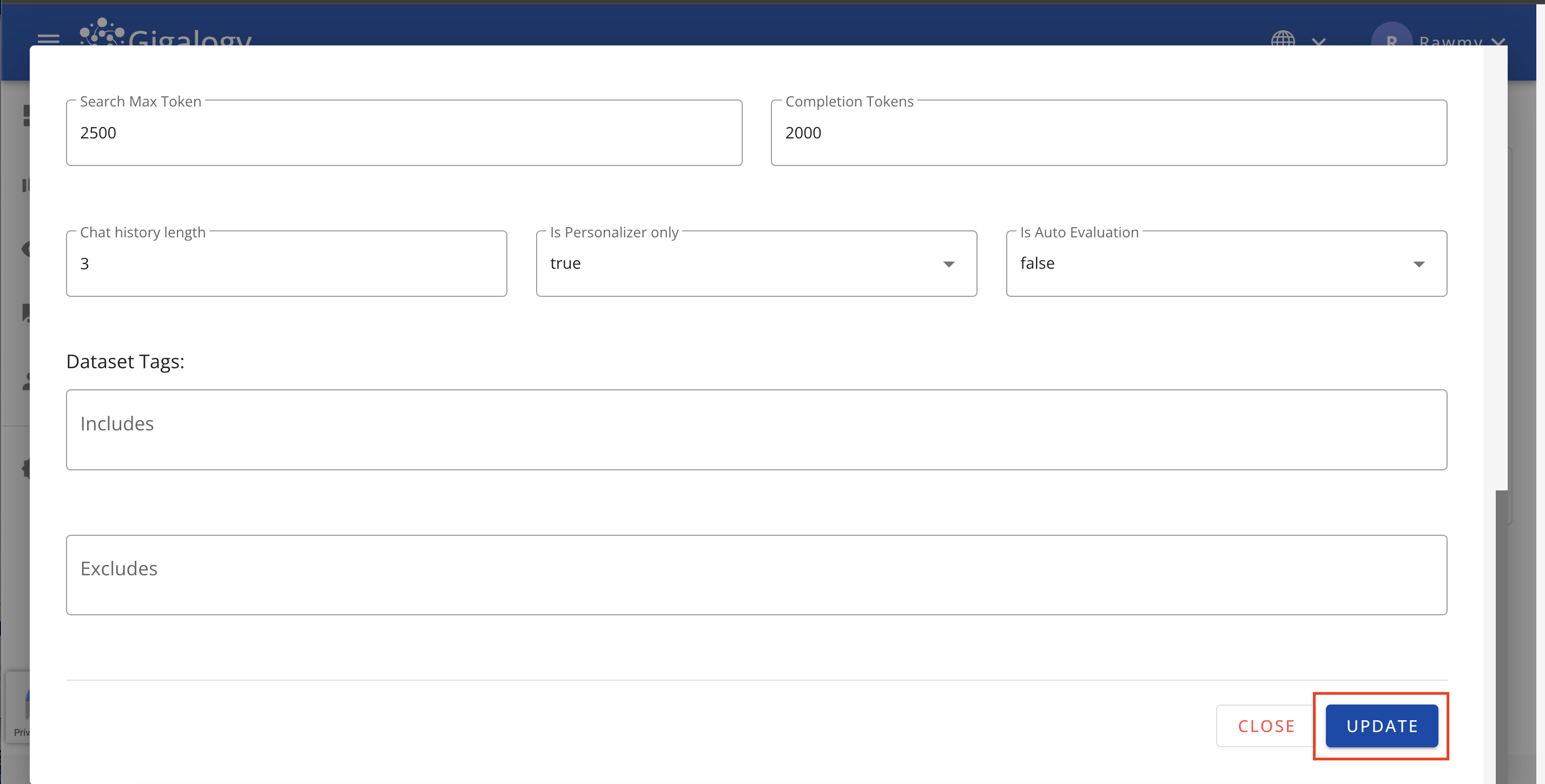
既存のプロフィールを更新するには、PUT /v1/gpt/profiles/{profile_id}を使用します。
リクエストボディおよびパラメータの詳細は、上記のPOST /v1/gpt/profilesと同じです。そちらのセクションを参照してください。
ここでの唯一の違いは、更新するプロフィールを特定するためにprofile_idをパラメータとして必要とすることです。
プロフィールの削除
既存のプロフィールを削除するには、プロジェクトの「プロフィール」タブに移動し、ごみ箱のアイコンをクリックして確定してください。一度削除したプロフィールは復元できないことに留意してください。
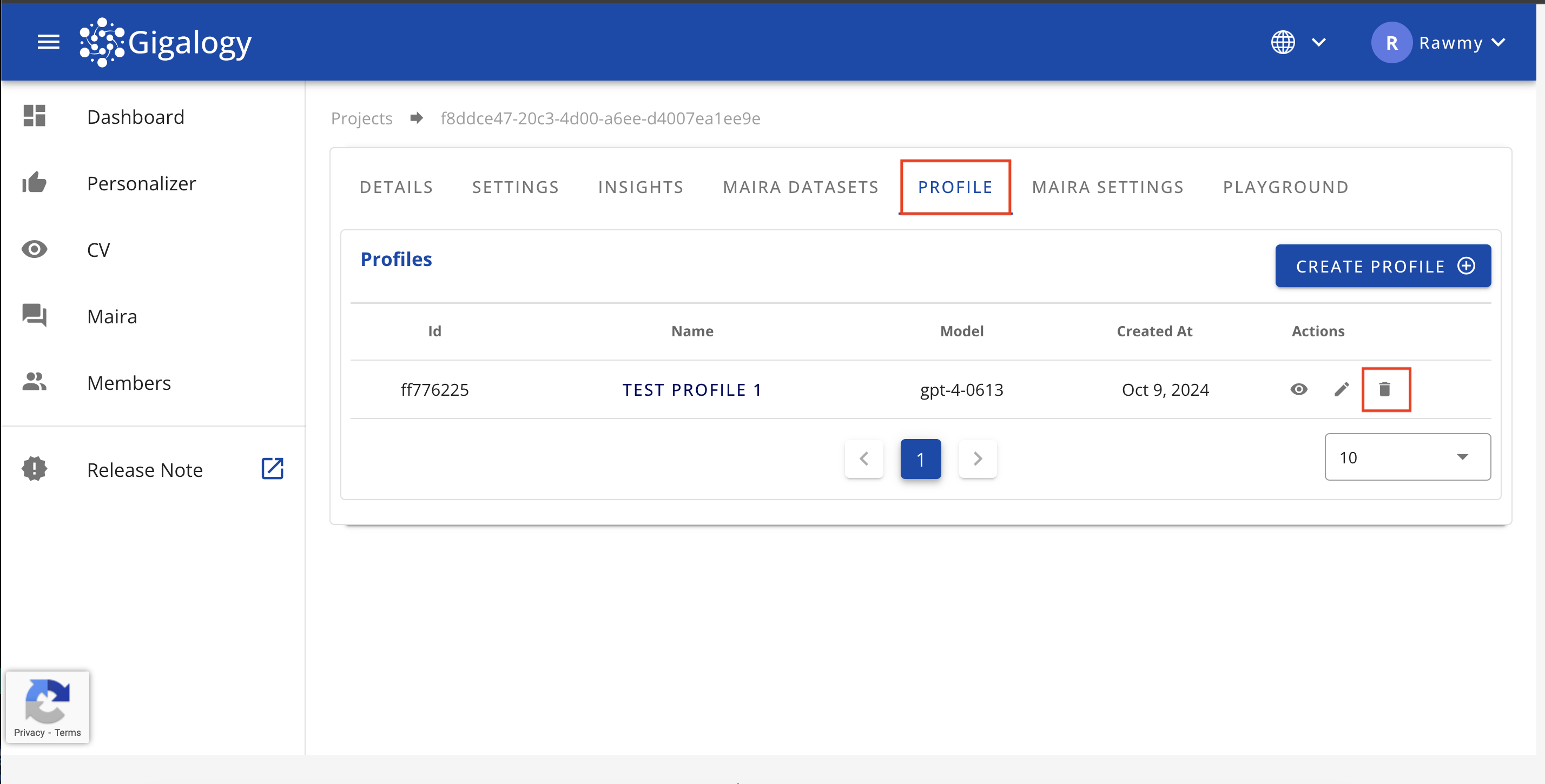
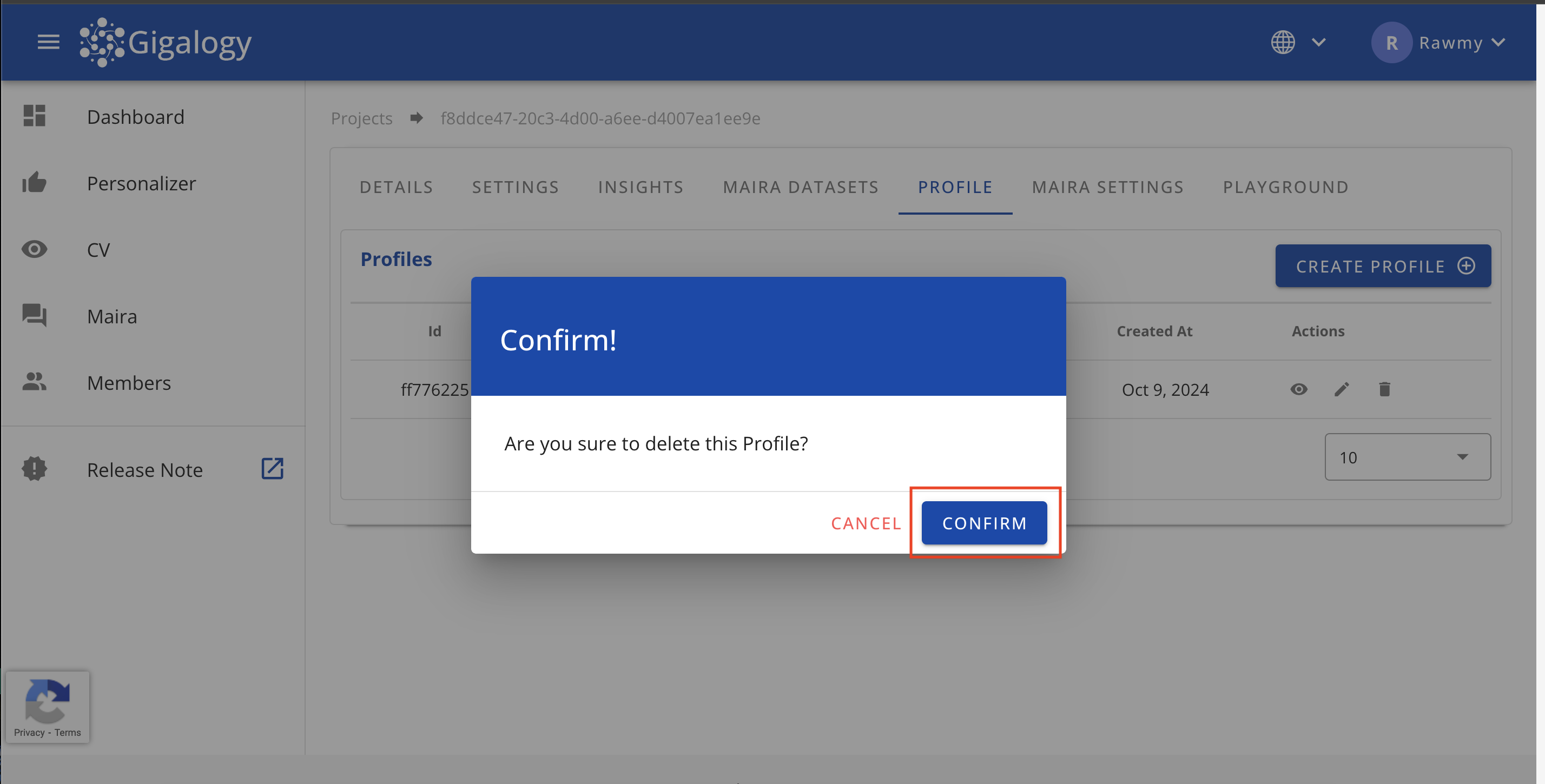
既存のプロフィールを削除するには、delete /v1/gpt/profiles/{profile_id}を使用します。このエンドポイントでは、削除したいプロフィールを特定するためにprofile_idがパラメータとして必要です。