Maira Profiles
GPT Profiles is a unique and powerful feature offered by Maira. When building a smart application or a customized GPT using Maira, this feature allows you to define the purpose, personality, response instructions, and other key settings. These settings will then be considered along with the context of your prompt.
You can create multiple profiles and switch between them as necessary. Below, we will explore this feature in more detail.
Note that you must have at least one profile to use Maira. You also have to define a default profile, which will be used if you do not pass a profile_id with any of your prompt. As you go through this document, this concepts will be more clear.
Create a new Profile
After creating a new project, you will be taken to the project "Setup" page, till you finish the initial setup of the project. This setup has three steps:
- Profile setup
- Dataset Upload
- Dataset Training
In this section, we will focus on the first step i.e "Profile" setup.
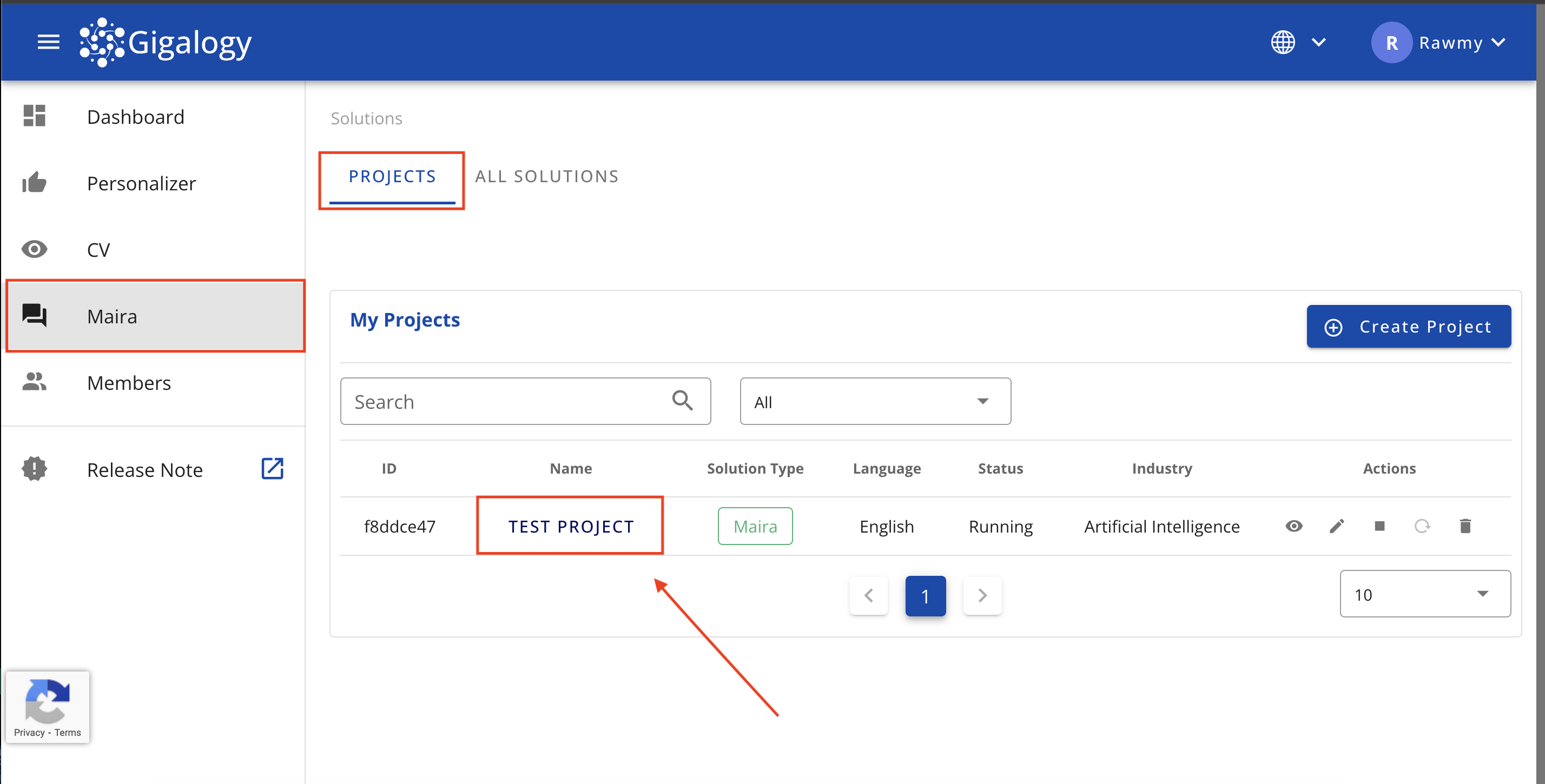
First Navigate to Maira solutions page and click on your project.
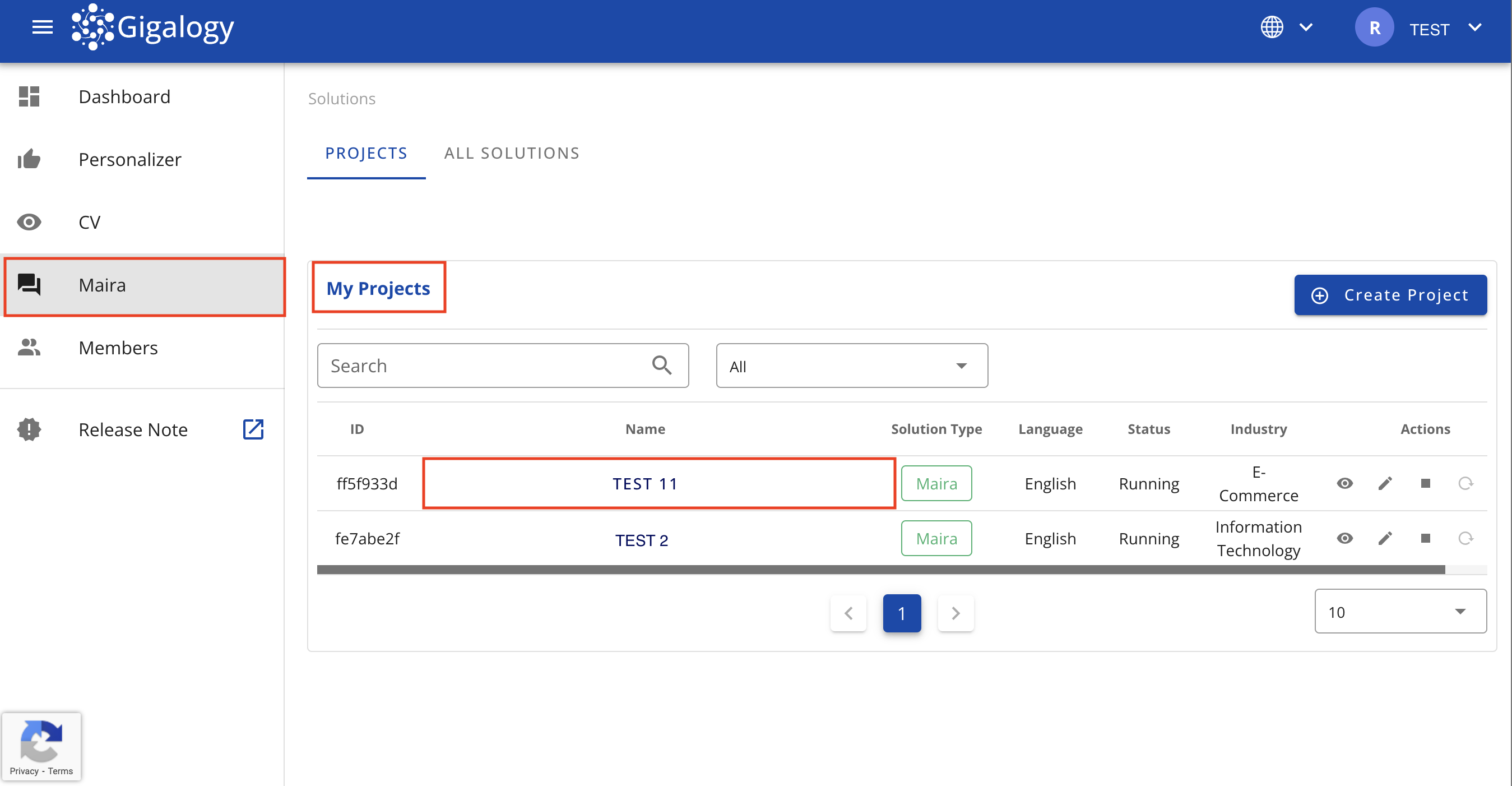
You will land in the below "Setup" step, where you have to create your first "Profile". Find the description of each parameter below
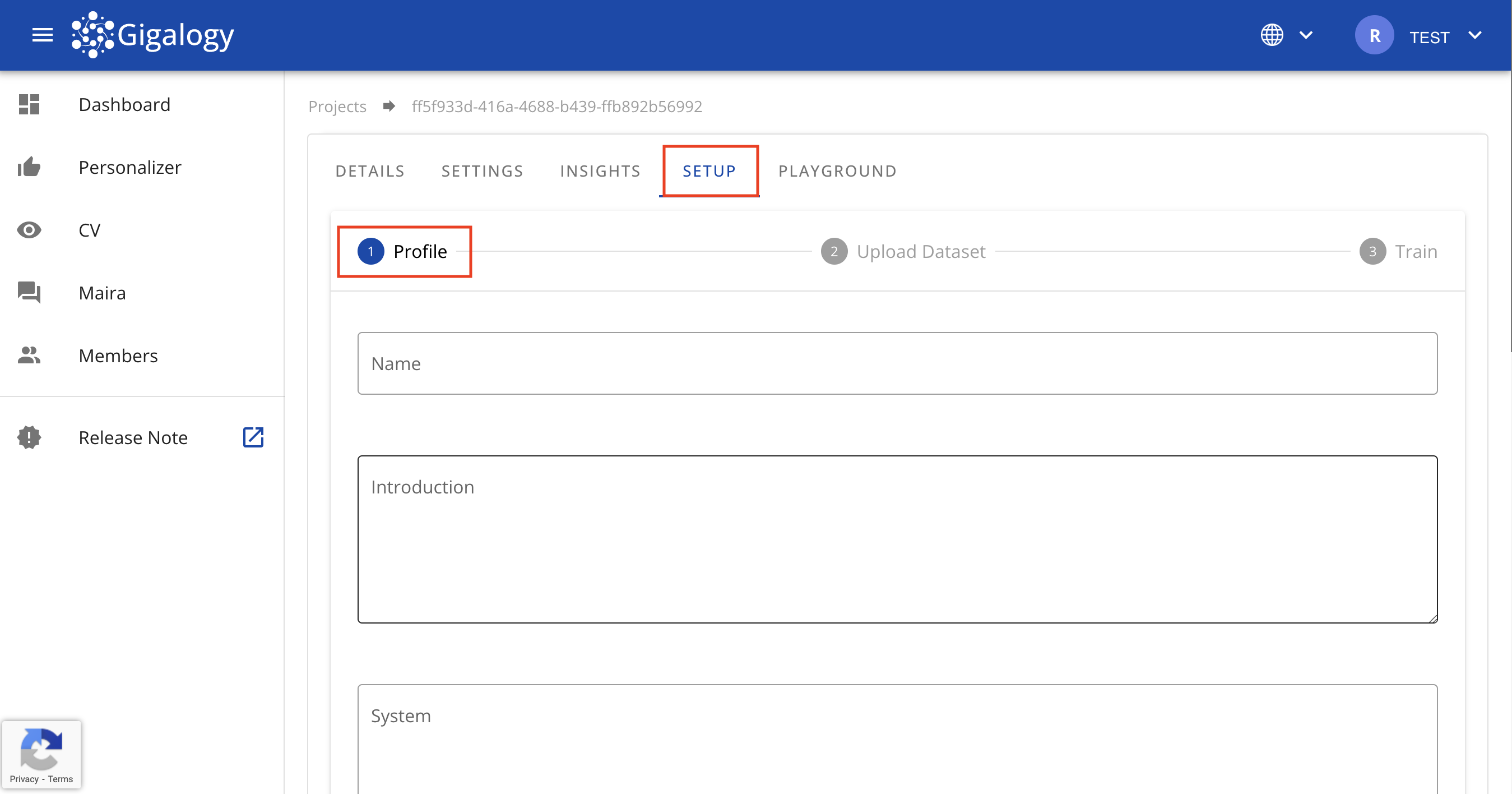
-
Name: Give a name to your profile, so that admins can easily understand its purpose.
-
Intro: Maira includes a feature that allows you to set specific instructions and rules for the AI, guiding how it generates responses.
- Example: Always respond with concise and professional language while addressing the query directly. Ask three follow-up questions after each response. If you don't know the answer, say sorry and do not generate random answer.
-
System: This is a large language model (LLM) feature designed to set a mode or persona for the AI.
- Example : You are a fitness coach, who provides personalized workout plans and nutrition advice based on individual goals and fitness levels.
-
Instructions: Use this section to provide clear guidance to end-users on how to interact with this specific profile. These instructions help users understand the scope, capabilities, and limitations of the profile, ensuring more efficient and relevant interactions.
- General Guidelines for Writing Instructions:
- Clearly state what types of questions or requests are appropriate for this profile.
- Specify any limitations or topics that are out of scope.
- Tailor the instructions to the datasets and features available to this profile.
- Optionally, include best practices or tips for getting the most accurate responses.
- Examples:
- "You can ask about product features, troubleshooting steps, and account management."
- "I can provide product recommendations and answer basic questions. For billing or sensitive account issues, please contact support via email."
- "This chatbot is for HR-related consultation only. Please do not submit personal medical information."
- "Ask me about fitness routines, nutrition advice, or general wellness tips. For medical emergencies, consult ça healthcare professional."
- Note: Each profile may have different instructions based on its purpose and available data. Providing clear instructions improves user experience and helps set expectations.
- General Guidelines for Writing Instructions:
-
Model: You can select the GPT model you want to use based on your needs from the dropdown. Please consider the purpose and the estimated token count when selecting the model, as this can significantly impact costs. You can learn more about OpenAI models from this page. This setting will impact the parameters
search_max_token(tokens allocated for data sent to the model) andcompletion_token(tokens allocated for the reply). Note thatintro,system, andqueryhave token costs that are not included in the token size allocation. The selected model'sCONTEXT WINDOWshould cover the total token allocation. That isCONTEXT WINDOW≥search_max_token+completion_token+intro+system+query. -
Temperature: The range of temperature is between 0-2. A lower temperature (closer to 0) makes the output more deterministic and focused, meaning the model will choose more likely words. A higher temperature (closer to 2) makes the output more random and creative, with a wider range of word choices.
-
top_p: An alternative to sampling with temperature, top_p also known as nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered. In simple terms, when this value is between 0.1 to 0.3, your responses will be more grounded to the reference documents and instruction. The higher it is, it will be more creative and prone to hallucination. It is good to test and find the right value for your project.
-
top_k: (Anthropic models only): This controls how many of the most likely next words the model considers when generating a response. For example, if top_k is set to 10, the model will only choose from the 10 most likely next tokens. A lower value (e.g., 1–10) makes responses more focused and deterministic. A higher value (e.g., 30–50) allows for more diversity and creativity but may introduce randomness or off-topic content. Adjust this based on how grounded or exploratory you want the responses to be.
-
Frequency Penalty: A parameter that reduces the likelihood of the model repeating the same tokens in its output. It penalizes frequent token usage, encouraging more diverse word choices.
- If frequency_penalty = 0.0, there is no penalty, and the model is free to repeat tokens.
- Higher frequency_penalty values make the model less likely to repeat words, promoting more variation in the output.
-
Presence Penalty: Default=0.0, ge=0.0, le=2.0. A parameter that encourages the model to introduce new tokens by penalizing tokens that have already appeared in the output. This drives the model to use less common or new words.
-
Stop: stop determines when the model should stop generating texts(tokens). If a list of strings(up to 4 allowed) e.g. ["world", "coding"] provided, and model encounters any of them, it stops generating texts. Say, model generated
hello world.worldis in thestopsequence, so model will stop at hello and returns. Another example is model has so far generatedI love codingand last token coding is instopsequence. So model will stop generating new token and returnI love. Stop sequence is an optional parameter, it defaults to an empty list. So model will continue generating tokens until the response finishes naturally. -
access_tags: Access tags are used to restrict which profiles guest users can access. See the Guest User Management tutorial to learn how to add guest users.
-
search max token: This is the number of tokens allocated for context sent to the model. Default values are dynamic, each model has specific defaults. When search max token 0, GAIP will completely ignore internal database.
-
Completion Tokens: Default=2000, example=2500. This is the number of tokens allocated for the reply
-
Chat History Length: The number of past conversations retained as context for submission to GPT.
-
Is Personalizer Only: Is this profile for personalizer use only, default value
FalseLearn more
This parameter impacts the context sent to Maira. If"is_personalizer_only": truethen all dataset uploaded through datasets endpoints will be ignored, restricting the context to product catalog only. When"is_personalizer_only": false, then both Maira dataset and item catalog of personalizer will be used for context
-
Is Auto Evaluation: Determines weather the conversation evaluation run automatically after each conversation. (We will cover evaluation in detail in the Evaluation Tutorial). This is an optional field. Please note that evaluation is resource intensive, and can be run manually via another endpoint (Covered in the Evaluations tutorial).
-
Search Mode: Specifies the type of search. Acceptable values are "context", "full_text", or "hybrid".
- Context Mode: Uses AI-powered contextual search to understand meaning and find relevant content from the datasets.
- Full Text Mode: Uses keyword-based search to find relevant content from the datasets,
- Hybrid Mode: Automatically decides whether to use contextual search based on the query
NOTE:
is_keyword_enabledinv1/maira/ask, acts as a "keyword boost" for contextual search only. It adds keyword filtering on top of vector similarity search when enabled, but has no impact when usingfull_textsearch mode. -
Dataset Languages: - A list of language codes used to translate user queries before document retrieval. This improves relevance when the dataset is primarily in a different language than the query. If left empty, no translation is performed.
- Supported values:
en(English),ja(Japanese),ko(Korean). - When to use it: For example, if your dataset is mainly in Japanese but users submit queries in English, set this to ja. The system will translate the query to Japanese before retrieving documents, resulting in more accurate responses.
- Supported values:
-
Dataset Tags: Which dataset tags should be included or excluded from context building. If not provided, then all datasets are considered for context building (We have talked about adding tags to dataset in the "dataset management" tutorial)
- Include: Tags to include in context generation, all datasets beyond these tags are excluded
- Exclude: Tags to exclude in context generation, all datasets beyond these tags are included
Once initial setup is completed, you can see a list of all your profiles in the "Profiles" table
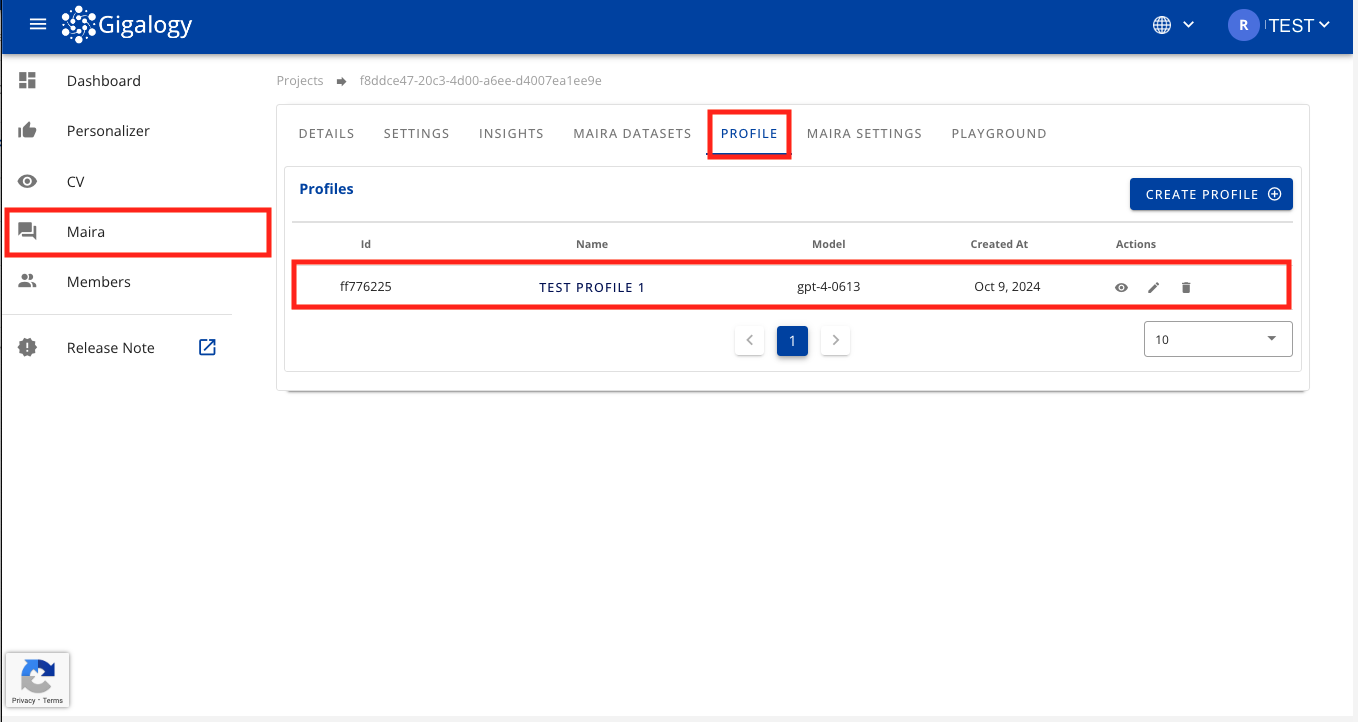
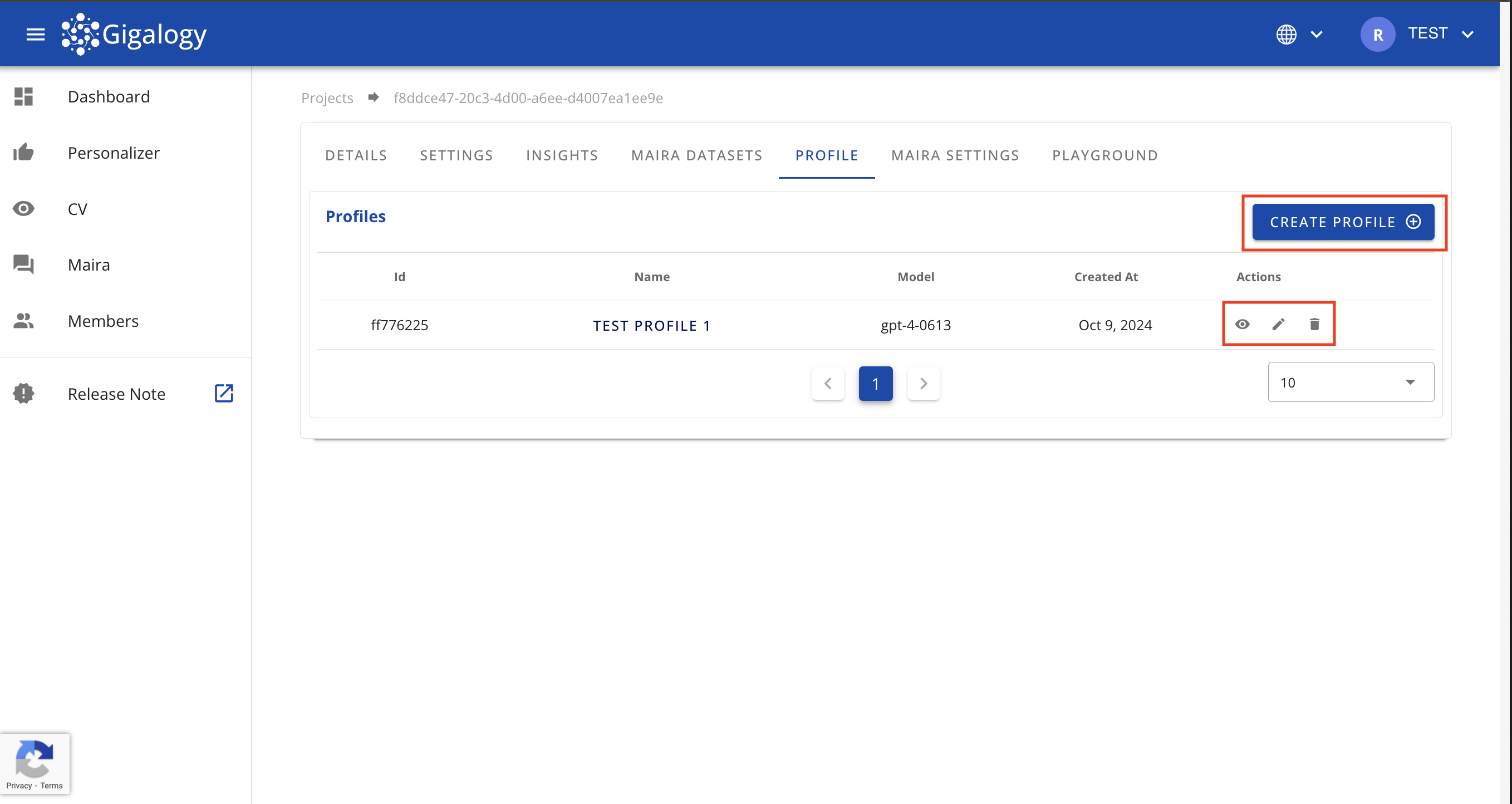
From this page, you can create a new profile by clicking on the "CREATE PROFILE" button or edit or delete an existing profile with the button in the "Actions" column.
To create a new Profile, use the endpoint POST /v1/gpt/profiles. Here is an sample request below:
{
"name": "Give a meaningful name to the profile",
"intro": "Describe your context format and expected output format.",
"system": "Set the personality of the GPT.",
"instructions": "Provide instructions to the user.",
"model": "gpt-3.5-turbo-0125",
"temperature": 0,
"top_p": 1,
"top_k": 100,
"frequency_penalty": 0,
"presence_penalty": 0,
"stop": [
"AI:",
"Human:"
],
"response_format": "json_object",
"search_max_token": 2500,
"completion_token": 2500,
"vision_settings": {
"resolution": "low or high. default is low",
"is_image_context_enabled": true
},
"chat_history_length": 3,
"is_personalizer_only": false,
"dataset_tags": {
"includes": [
"tag1",
"tag2"
],
"excludes": [
"tag1",
"tag2"
]
},
"is_auto_evaluation": false,
"is_lang_auto_detect": true
"search_mode": "context",
"dataset_languages": [
"en",
"ja"
]
}
Let's go through each parameters
-
name: str - Give a name to your profile, so that admins can easily understand its purpose.
-
intro: str - Maira includes a feature that allows you to set specific instructions and rules for the AI, guiding how it generates responses.
- Example: Always respond with concise and professional language while addressing the query directly. Ask three follow-up questions after each response. If you don't know the answer, say sorry and do not generate random answer.
-
system: str - TThis is a large language model (LLM) feature designed to set a mode or persona for the AI.
- Example: You are a fitness coach, who provides personalized workout plans and nutrition advice based on individual goals and fitness levels.
-
instructions: (optional) - Use this section to provide clear guidance to end-users on how to interact with this specific profile. These instructions help users understand the scope, capabilities, and limitations of the profile, ensuring more efficient and relevant interactions.
- General Guidelines for Writing Instructions:
- Clearly state what types of questions or requests are appropriate for this profile.
- Specify any limitations or topics that are out of scope.
- Tailor the instructions to the datasets and features available to this profile.
- Optionally, include best practices or tips for getting the most accurate responses.
- Examples:
- "You can ask about product features, troubleshooting steps, and account management."
- "I can provide product recommendations and answer basic questions. For billing or sensitive account issues, please contact support via email."
- "This chatbot is for HR-related consultation only. Please do not submit personal medical information."
- "Ask me about fitness routines, nutrition advice, or general wellness tips. For medical emergencies, consult ça healthcare professional."
- Note: Each profile may have different instructions based on its purpose and available data. Providing clear instructions improves user experience and helps set expectations.
- General Guidelines for Writing Instructions:
-
model: str - You can select the GPT model you want to use based on your needs. Please consider the purpose and the estimated token count when selecting the model, as this can significantly impact costs. You can learn more about OpenAI models from this page. This setting will impact the parameters
search_max_token(tokens allocated for data sent to the model) andcompletion_token(tokens allocated for the reply). Note thatintro,system, andqueryhave token costs that are not included in the token size allocation. The selected model'sCONTEXT WINDOWshould cover the total token allocation. That isCONTEXT WINDOW≥search_max_token+completion_token+intro+system+query.- Select the model, your Possible values are
gpt-3.5-turbo-0125,gpt-3.5-turbo-0613,gpt-3.5-turbo-instruct,gpt-3.5-turbo-16k-0613,gpt-3.5-turbo-1106,gpt-4-0613,gpt-4-1106-preview,gpt-4-0125-preview,gpt-4-turbo-2024-04-09,gpt-4o-2024-05-13,gpt-4-vision-preview,gpt-4o-mini,gpt-4o-mini-2024-07-18,gpt-4o-2024-08-06
- Select the model, your Possible values are
-
temperature: Optional[float] - Default=0.0, ge=0.0, le=2.0. A lower temperature (closer to 0) makes the output more deterministic and focused, meaning the model will choose more likely words. A higher temperature (closer to 2) makes the output more random and creative, with a wider range of word choices.
-
top_p: Optional[float] - An alternative to sampling with temperature, top_p also known as nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered. In simple terms, when this value is between 0.1 to 0.3, your responses will be more grounded to the reference documents and instruction. The higher it is, it will be more creative and prone to hallucination. It is good to test and find the right value for your project.
-
top_k: Optional[int] - (Anthropic models only): This controls how many of the most likely next words the model considers when generating a response. For example, if top_k is set to 10, the model will only choose from the 10 most likely next tokens. A lower value (e.g., 1–10) makes responses more focused and deterministic. A higher value (e.g., 30–50) allows for more diversity and creativity but may introduce randomness or off-topic content. Adjust this based on how grounded or exploratory you want the responses to be.
-
frequency_penalty: Optional[float] - Default=0.0, ge=0.0, le=2.0. A parameter that reduces the likelihood of the model repeating the same tokens in its output. It penalizes frequent token usage, encouraging more diverse word choices.
- If frequency_penalty = 0.0, there is no penalty, and the model is free to repeat tokens.
- Higher frequency_penalty values make the model less likely to repeat words, promoting more variation in the output.
-
presence_penalty: Optional[float] - Default=0.0, ge=0.0, le=2.0. A parameter that encourages the model to introduce new tokens by penalizing tokens that have already appeared in the output. This drives the model to use less common or new words.
-
Stop: stop determines when the model should stop generating texts(tokens). If a list of strings(up to 4 allowed) e.g. ["world", "coding"] provided, and model encounters any of them, it stops generating texts. Say, model generated
hello world.worldis in thestopsequence, so model will stop at hello and returns. Another example is model has so far generatedI love codingand last token coding is instopsequence. So model will stop generating new token and return I love. Stop sequence is an optional parameter, it defaults to an empty list. So model will continue generating tokens until the response finishes naturally. -
access_tags: Access tags are used to restrict which profiles guest users can access. See the Guest User Management tutorial to learn how to add guest users.
-
response_format: Optional[str] - What is the expected response format, supported formats are
json_formatandtext. Ifjson_formatis selected, your intro or system must contain the word "json" somewhere. -
search_max_token: Optional[int] - This is the number of tokens allocated for context sent to the model. default values are dynamic now, each model has specific defaults. When search max token 0, GAIP will completely ignore internal database.
-
completion_token: Optional[int] - Default=2000, example=2500. This is the number of tokens allocated for the reply
-
vision_settings: Optional[Dict] - Required for vision models
- vision_settings.resolution: If resolution is
high, it will cost more but gives more accuracy in result,lowis the opposite. - vision_settings.is_image_context_enabled:
truemeans we will send images as context along with text context to the LLM.falsemeans only text context/reference is used.
- vision_settings.resolution: If resolution is
-
chat_history_length: Optional[int] - The number of past conversations retained as context for submission to GPT.
-
is_personalizer_only: Optional[bool] - Is this profile for personalizer use only, default value
FalseLearn more
This parameter impacts the context sent to Maira. If"is_personalizer_only": truethen all dataset uploaded through datasets endpoints will be ignored, restricting the context to product catalog only. When"is_personalizer_only": false, then both Maira dataset and item catalog of personalizer will be used for context
-
dataset_tags: Optional[Dict] - Which dataset tags should be included or excluded from context building. If not provided, then all datasets are considered for context building (We have talked about adding tags to dataset in the "dataset management" tutorial)
- dataset_tags.include: Optional[list[str]] - Tags to include in context generation, all datasets beyond these tags are excluded
- dataset_tags.exclude: Optional[list[str]] - Tags to exclude in context generation, all datasets beyond these tags are included
-
is_auto_evaluation: Optional[bool] - Determines weather the conversation evaluation run automatically after each conversation. (We will cover evaluation in detail in the Evaluation Tutorial). This is an optional field. Please note that evaluation is resource intensive, and can be run manually via another endpoint (Covered in the Evaluations tutorial).
-
is_lang_auto_detect: Optional[bool] - Default value is
true. When set tofalse, automated language detection from the query will be disabled.- What it does: Detects the language of the query and instructs the AI model to respond in the same language, ensuring the response always comes in the expected language.
- NOTE: When both
is_lang_auto_detectin the profile and an explicitlanguagefield from the/v1/maira/askrequest body are used together,is_lang_auto_detecttakes priority. - Example: If the query is in English and
is_lang_auto_detect=truein the profile, but the request body setslanguage=ja, the response will still be in English (the detected query language).
-
search_mode: Optional. - Specifies the type of search. Acceptable values are "context", "full_text", or "hybrid".
- Context Mode: Uses AI-powered contextual search to understand meaning and find relevant content from the datasets.
- Full Text Mode: Uses keyword-based search to find relevant content from the datasets,
- Hybrid Mode: Automatically decides whether to use contextual search based on the query
NOTE:
is_keyword_enabledinv1/maira/ask, acts as a "keyword boost" for contextual search only. It adds keyword filtering on top of vector similarity search when enabled, but has no impact when usingfull_textsearch mode. -
dataset_languages: Optional[List[str]] - A list of language codes used to translate user queries before document retrieval. This improves relevance when the dataset is primarily in a different language than the query. If left empty, no translation is performed.
- Supported values:
en(English),ja(Japanese),ko(Korean). - When to use it: For example, if your dataset is mainly in Japanese but users submit queries in English, set this to ja. The system will translate the query to Japanese before retrieving documents, resulting in more accurate responses.
- Supported values:
Example request body
Here is an example request body below, using which you can hit the profile and make a test Maira Profile (with the mandatory parameters only).
{
"name": "My first test profile",
"intro": "Reply concisely and objectively in a easy to read and polite way",
"system": "You are a bot to support my work",
"model": "gpt-4o-mini-2024-07-18",
"temperature": 0,
"top_p": 1,
"frequency_penalty": 0,
"presence_penalty": 0,
"stop": [
"Human:"
],
"access_tags": [
"ML",
"AI",
"Business",
"HR"
],
"search_max_token": 2500,
"completion_token": 2500,
"vision_settings": {},
"chat_history_length": 3,
"is_personalizer_only": false,
"dataset_tags": {
"includes": [],
"excludes": []
}
}
Successful response looks like this:
{
"detail": {
"response": "GPT profile created successfully",
"profile_id": "cfe76e28-bef9-45c8-bf5b-1f4b0117b176",
"name": "My first test profile"
}
}
The the profile_id is included un the response
View existing Profile
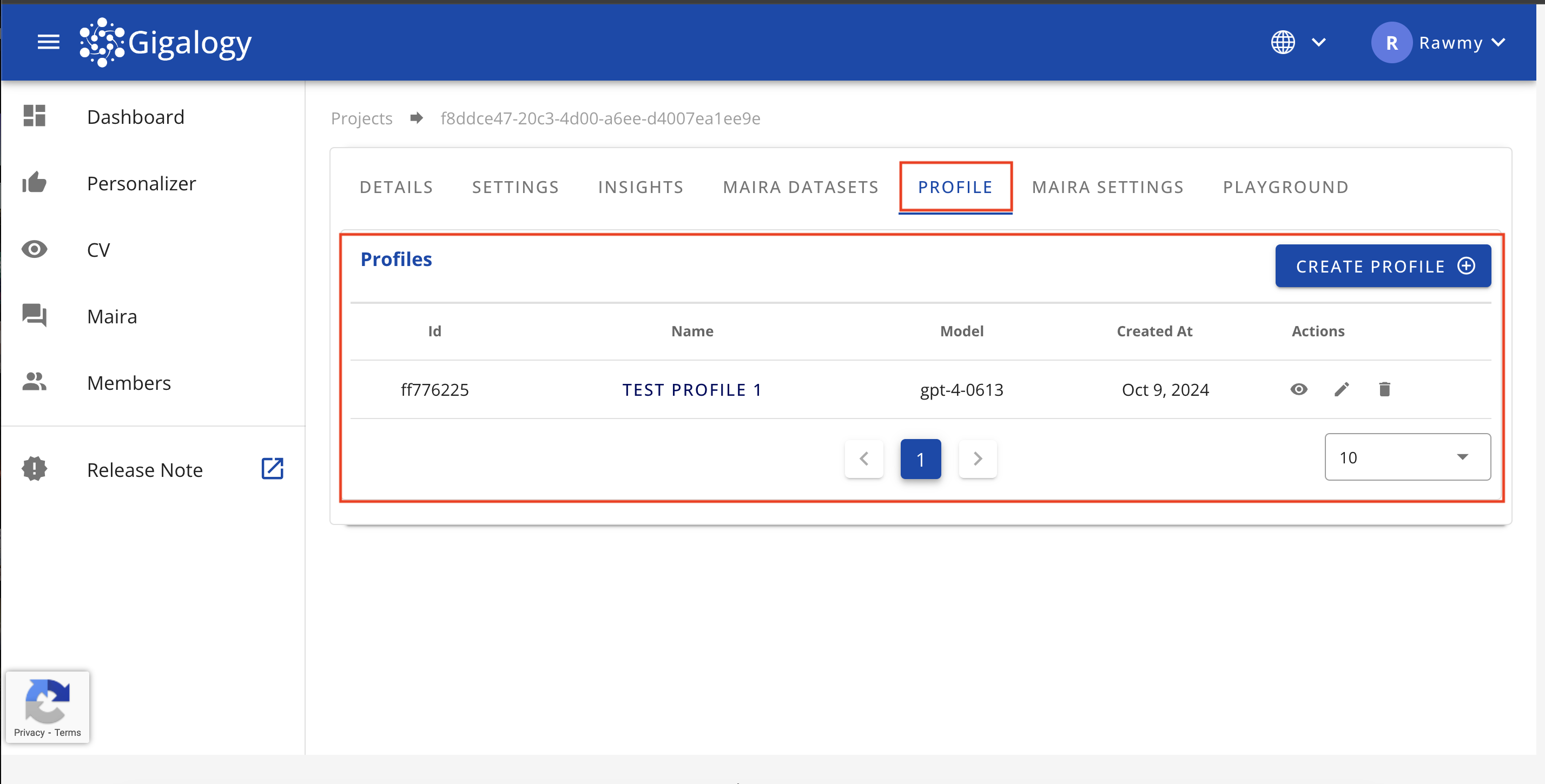
View all existing profiles
To view all existing profiles of a project, simply navigate to the "PROFILE" tab of your Project. There in the "Profiles" tab, you will see list of all your existing profiles.
Use GET /v1/gpt/profiles for all existing profiles
It takes below parameters:
- start: Optional[int] - The starting index for profile retrieval (default is 0, minimum is 0).
- size: Optional[int] - The number of profiles to retrieve (default is 10, minimum is 1).
The response includes the metadata of the profiles.
View details of a profile
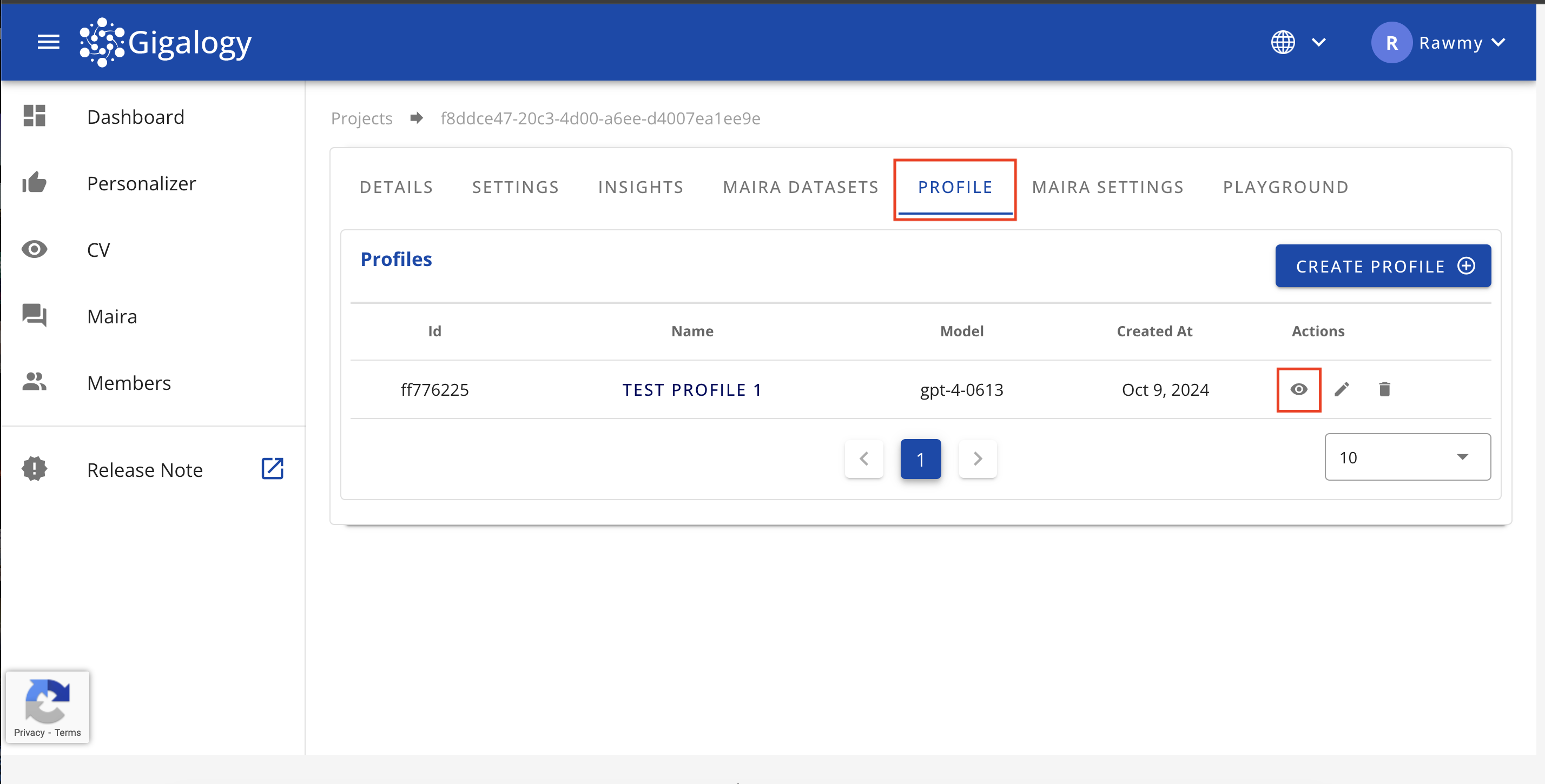
To see the details of an existing profile, navigate to the "PROFILE" tab of your project and click on the Eye mark to see the detail of the profile.
Use GET /v1/gpt/profiles/{profile_id} to view the details of a specific profile.
This takes the profile_id as the only parameter.
The response will include the full detail of the specified profile.
Update a Profile
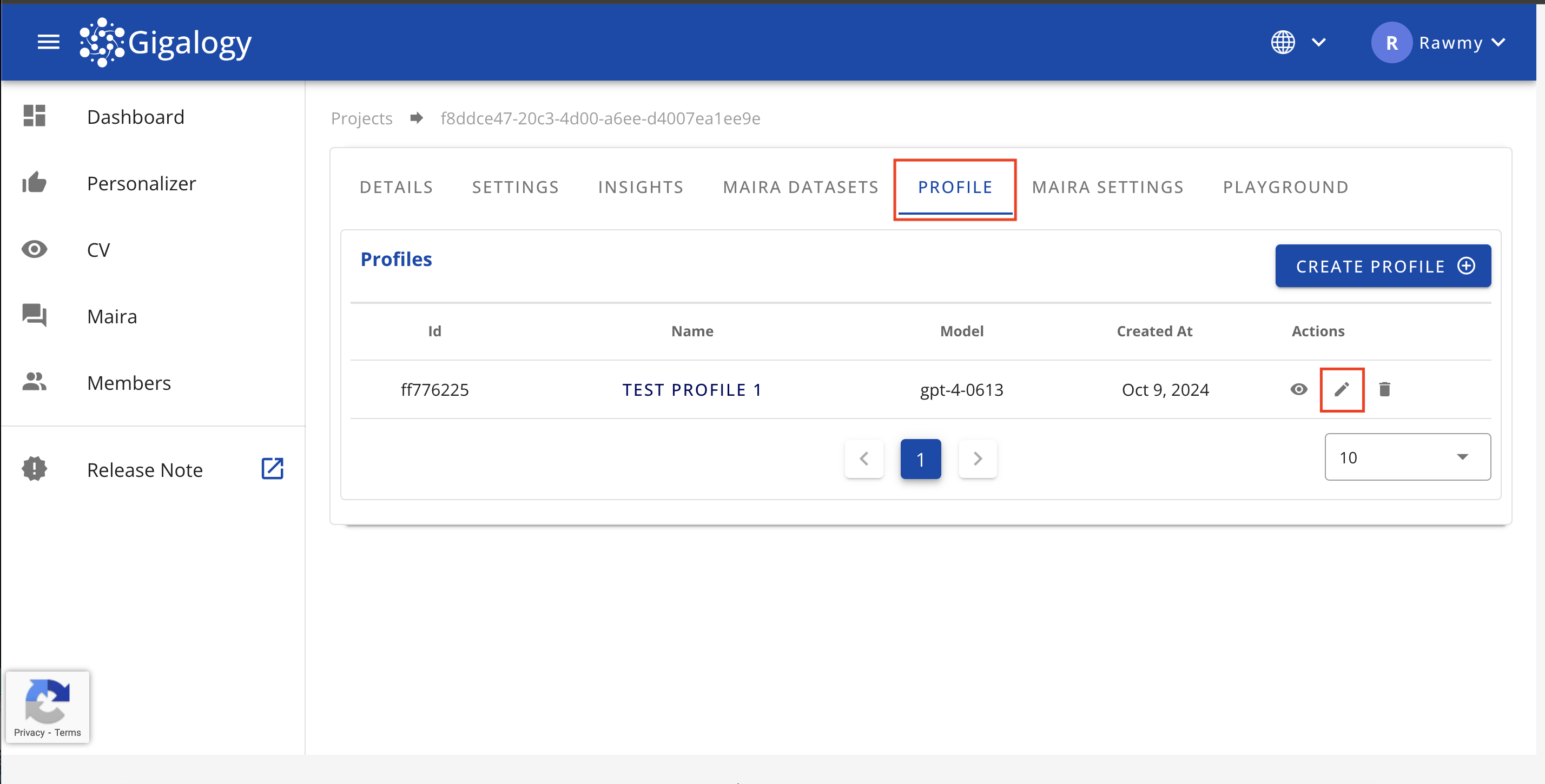
To update the an existing profile, navigate to the "PROFILE" tab of your project and click on the Pencil mark. A modal will open where you can edit the profile detail.
After update is done, click on the "UPDATE" button to confirm the changes and close the modal
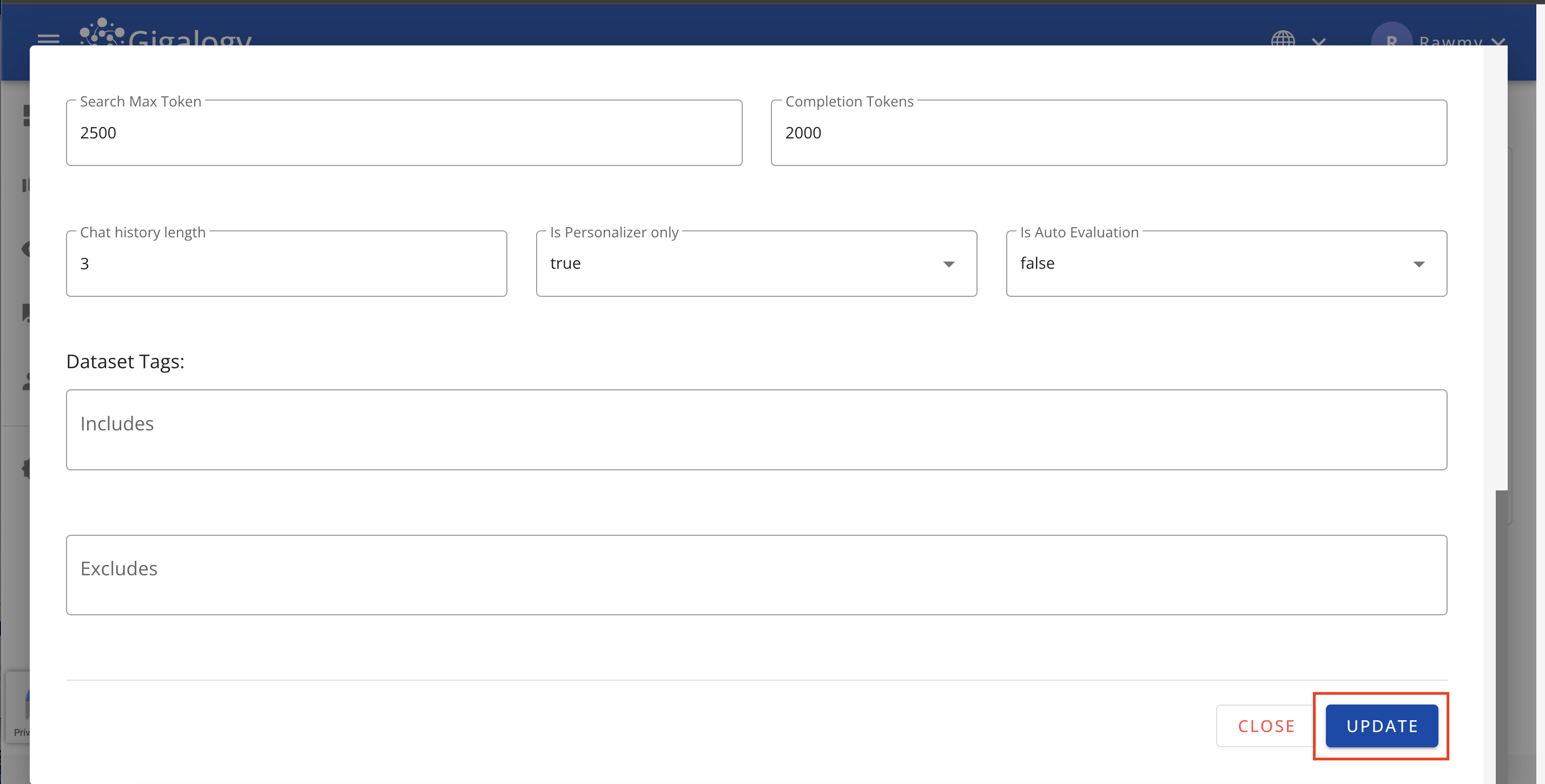
To update and existing profile, use PUT /v1/gpt/profiles/{profile_id}.
The request body and parameter details are same as above POST /v1/gpt/profiles. Please refer to that section.
Only difference here is that it will take the profile_id as a parameter, where you identify which profile you want to update.
Delete a Profile
To delete an existing profile, navigate to the "PROFILE" tab of your project and click on the Trash mark and confirm. Be aware that deleted profiles cannot be retrieved.
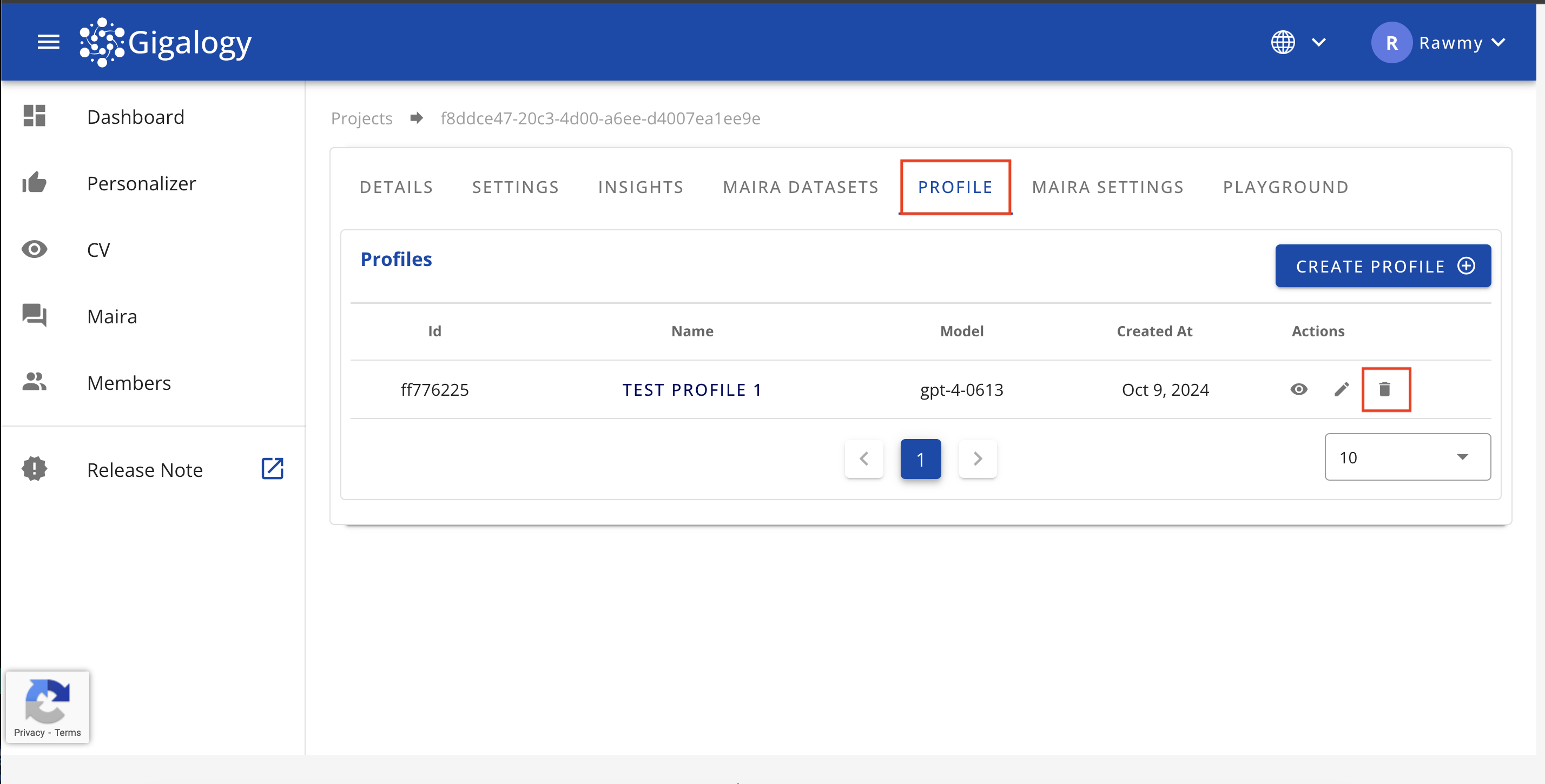
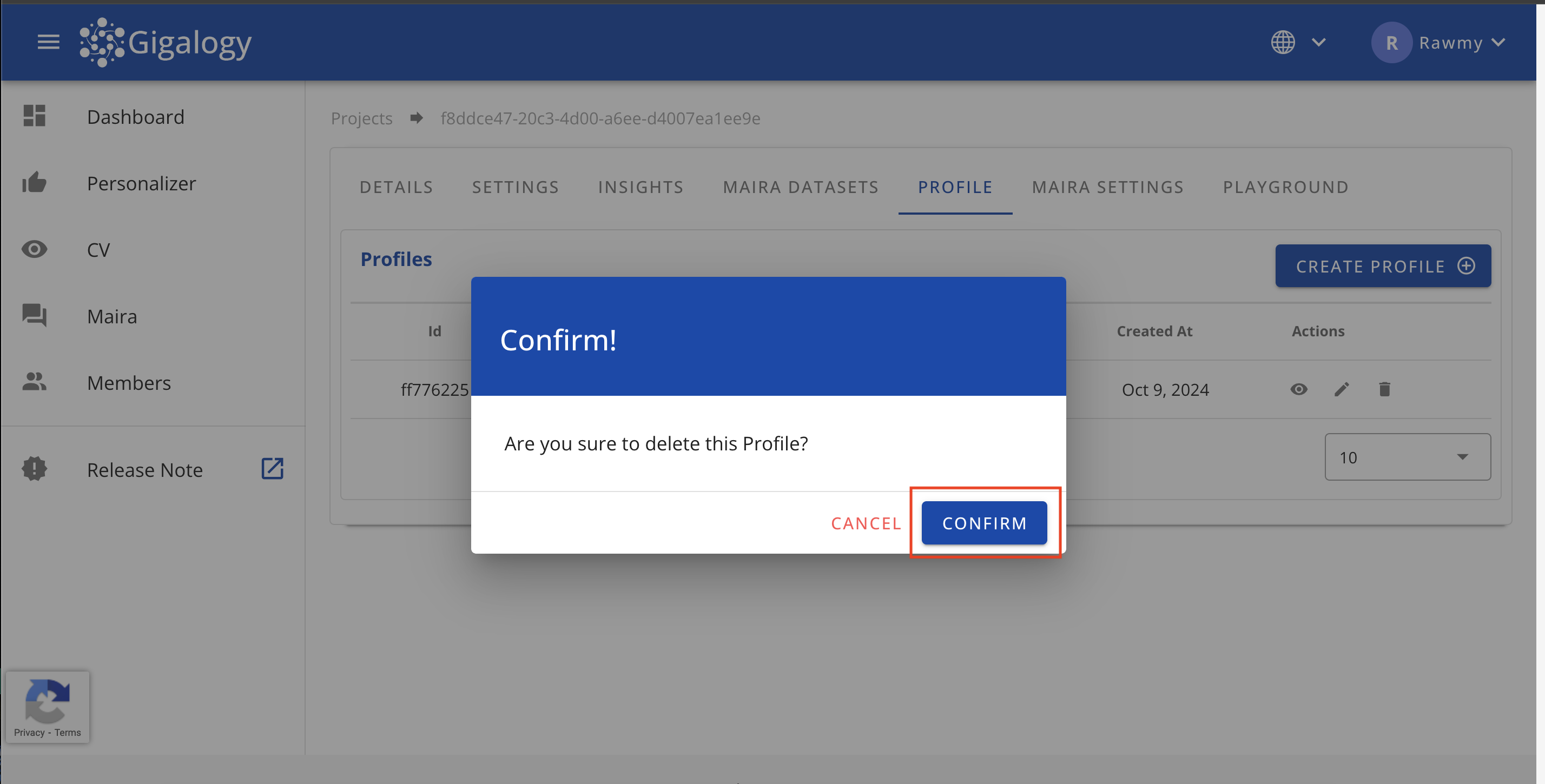
Use delete /v1/gpt/profiles/{profile_id} to delete an existing profile.
This endpoint takes profile_id as a parameter, where you identify which profile you want to delete.